






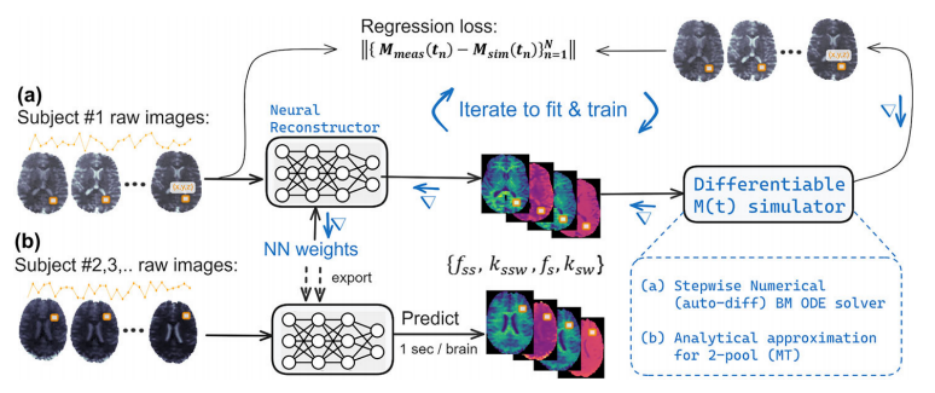
近年来,第一性原理计算与深度学习技术的交叉融合正在推动计算材料科学进入智能化研究的新阶段。密度泛函理论(DFT)作为材料模拟的黄金标准,能够从量子力学层面精确解析材料的电子结构和物理化学性质(Kohn & Sham, 1965)。然而,传统DFT计算面临计算成本高昂和泛函精度受限等挑战。深度学习技术的引入为解决这些问题提供了创新方案,开创了"AI for Materials"的新范式。
ML-FFs不仅以惊人的方式学习并复现量子力学的复杂规律,更将模拟的边界推向了前所未有的广度和深度。我们正见证着一个新时代的黎明:从原子尺度精准设计下一代能源材料、高效催化剂,到揭示生命过程中关键分子的动态奥秘,ML-FFs正以前所未有的能力赋能科学家。顶级期刊上的成果井喷,正是这一变革力量的有力证明。这不仅仅是计算工具的升级,更是科研思维与发现模式的革新。然而,驾驭这强大的“AI引擎”,需要融合量子物理的智慧、分子模拟的技艺与机器学习的精髓。本课程正是为此而生,旨在为您点亮通往这一前沿领域的灯塔,助您成为新一代计算科学的弄潮儿。
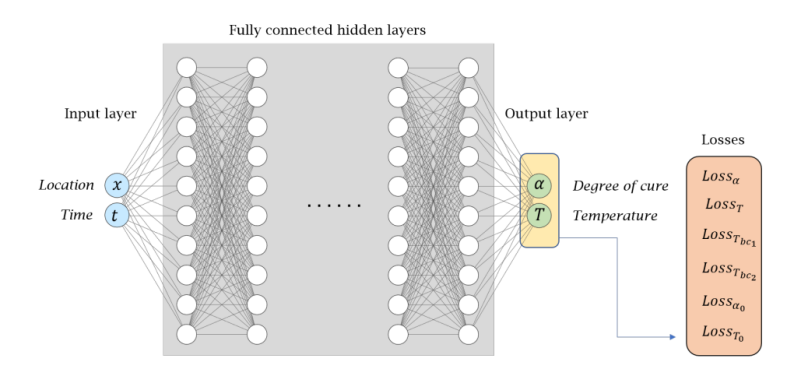
随着工程问题的复杂性日益增加,传统结构力学分析方法在处理多物理场耦合、非线性行为和高维数据时面临计算效率与精度的双重挑战。人工智能(AI),特别是深度学习技术的迅猛发展,为结构力学与仿真领域带来了革命性机遇。物理信息神经网络(PINN)、卷积神经网络(CNN)、图神经网络(GNN)等前沿算法正在重塑偏微分方程(PDE)求解、结构优化和参数反演的范式,为智能设计与高效仿真开辟了新路径。
专题一:机器学习分子动力学
专题二:深度学习第一性原理
专题三:人工智能辅助材料设计
专题四:人工智能助力结构力学应用与仿真
专题五:人工智能技术高性能计算偏微分方程及其应用
01
机器学习分子动力学
机器学习分子动力学本次“机器学习分子动力学专题研修班”旨在帮助学员系统掌握AI4Science时代下机器学习力场的核心理论与实践技能。通过为期五天的强化学习,学员将能够:
1.快速认知:量子化学计算在ML-FF数据生产中的角色与基本操作。
2.入门和理解:机器学习的基本原理、神经网络核心概念及其在分子模拟中的应用。
3.熟练运用:LAMMPS分子动力学模拟软件进行传统模拟与ML-FF驱动的模拟。
4.精通掌握:以DeePMD-kit系列和MACE为代表的先进机器学习力场模型的理论、构建、训练与验证方法。
5.深入了解:NequIP、Allegro等具有超高数据效率的等变模型,理解其核心思想与优势,从而显著减轻高昂的数据生产成本。
6.掌握运用:机器学习力场领域的“ChatGPT”产品——开箱即用、免费开源的通用大模型(如MACE-OFF23, MACE-MP0, DPA系列)及其微调技巧。
7.实践操作:课程将附带大量相关代码与示例脚本,确保学员通过实操提升解决实际科研问题的能力。
02
深度学习第一性原理
1.深化学习理论基础:掌握薛定谔方程、DFT原理及交换-相关泛函的影响机制
2.熟练掌握计算技能:完成材料建模→结构优化→电子结构计算全流程,优化平面波基组参数
3.材料特征工程学习:构建二维材料拓扑/光谱特征,开发材料性能预测模型(如催化剂、硬度)
4.掌握神经网络机器学习融合方法:搭建CGCNN网络,实现分子动力学轨迹分析及材料属性预测
5.掌握综合应用实例:研究多物理场耦合(杨氏模量、热导率、超导材料)及缺陷体系(螺位错、薄膜生长)
6.掌握计算工具:Python(NumPy/Pandas/scikit-learn/tensor-flow)、pymatgen、机器与深度学习框架
03
人工智能辅助材料设计
内容涵盖了从基础Python编程到常见的机器学习算法,并通过实际案例分析与项目实践,帮助学员理解并掌握如何将机器学习技术应用于材料与化学领域。课程设计注重理论与实践的结合,逐步深入,让学员在学习过程中不仅能够掌握相关算法,还能亲自动手解决材料科学中的实际问题。
1.掌握Python编程基础及其在科学计算中的应用:学会利用Python进行数据处理、模型构建与可视化,熟悉NumPy、Pandas等工具。
2.理解材料与化学中的机器学习方法:掌握线性回归、逻辑回归、决策树、支持向量机等常见算法的基本原理与应用。
3.应用机器学习解决材料科学问题:通过项目实践,深入理解数据采集、特征选择、模型训练与评估等步骤,学会使用sklearn等工具库完成任务。
4.了解材料数据的特征工程与数据库应用:学习如何表示分子结构与晶体结构,并了解常见材料数据库的使用方法。
5.提升实战能力并引导深入学习:通过多样化的项目实践案例,巩固课程内容,为后续深度学习等更复杂算法的学习打下基础。
04
人工智能技术助力结构力学应用与仿真
本课程以问题驱动为核心,旨在培养学员在结构力学与人工智能交叉领域的建模、分析与创新能力。通过理论讲授、编程实操和前沿论文复现,学员将掌握从基础到高级的结构力学仿真技能,熟练运用Python、PINN和机器学习技术解决实际工程问题,同时洞悉该领域的最新发展趋势。
从零到一的建模能力:课程从结构力学基础(静力平衡、刚度矩阵、边界条件)出发,逐步扩展到多物理场耦合问题(如热-结构、流-结构)。通过Python实现有限元分析(FEA),结合PINN求解偏微分方程(PDE),学员将学习如何简化复杂现象、构建控制方程,并通过无量纲化分析关键参数。实操案例(如梁受力、2D框架模态分析)帮助学员掌握从问题定义到数值求解的完整流程,对比传统FEA与PINN的优劣,探索AI在结构力学中的潜力与局限。
05
人工智能技术高性能计算微偏分方程及其应用
通过五天的系统学习,使学员全面掌握AI驱动的PDE高性能计算方法,熟练运用物理信息神经网络(PINN)、Fourier Neural Operators等前沿技术,解决流体力学、复合材料、增材制造等领域的复杂PDE问题,并具备探索科研前沿的能力。课程通过理论讲解、代码实操和科研创新点说明,指导学员理解深度学习与PDE的融合,掌握Python高性能计算工具(如JAX)优化PDE求解的技巧,深入学习PINN在非线性PDE和多物理场耦合中的应用,探索Fourier Neural Operators在实时预测中的高效性,以及随机PDE、神经形态计算等前沿技术在复合材料和增材制造中的潜力。学员将通过实验和小组项目,复现科研成果,培养模型开发、性能优化和跨学科应用能力,为航空航天、能源、生物医学等领域的工程和科研奠定坚实基础,最终成为AI驱动PDE求解的创新实践者。
01
机器学习分子动力学
来自全国重点大学、国家“985工程”、“211工程"重点高校,长期从事固态电解质材料的第一性原理、分子动力学模拟研究,特别是在利用计算模拟方法和机器学习相结合来加速材料筛选,性能预测等方面有深入研究。他的授课方式浅显易懂,特别擅长从简单角度出发,逐渐深入讲解复杂的理论知识和计算方法!目前共发表论文(Nature Catalysis, Nature Communications, Energy & Environmental Science, Advanced Energy Materials等)共四十余篇。曾任Joule, Journal of Materials Chemstry A等期刊审稿人。
02
深度学习第一性原理
来自中国顶尖高校,在机器学习、深度学习算法与材料物理模拟领域拥有丰富的研究与教学经验,专注于深度学习算法优化、第一性原理计算与超导材料研究。多年来致力于运用机器学习和深度学习技术推动材料设计与性能优化,特别是在机器学习算法、二维材料及其同位素材料深度学习第一性原理模拟及超导材料物理方向取得了卓越成果。以第一作者或通讯作者身份在 Advanced Materials、Advanced Functional Materials、ACS Nano、Nano Letters 和 Physical Review B 等顶级期刊发表论文二十余篇。
03
人工智能辅助材料设计
陈老师来自国内“985工程”顶尖高校材料物理与化学专业,长期从事材料科学、机器学习,未来互联网与命名数据网络,量子力学等领域。在多个国际高水平期刊上发表 SCI检索论文15余篇。国家发明专利一项,他的授课方式深入浅出,能够将复杂的理论知识和计算方法讲解得清晰易懂,受到学员们的一致认可和高度评价!
4
人工智能技术助力结构力学应用与仿真,人工智能技术高性能计算微偏分方程及其应用
毕业于顶尖高校,拥有国内985院校背景,专注于复合材料、物理信息神经网络流体力学、结构力学、有限元分析及多物理场耦合研究。老师在深度学习与结构力学交叉领域积累了丰富经验,熟练运用物理信息神经网络(PINN)、卷积神经网络(CNN)、图神经网络(GNN)等技术解决静力学、动力学及非线性问题。近年来,老师在发表多篇高水平论文,研究方向涵盖弹性力学、热-结构耦合、材料非线性建模,以及AI驱动的结构优化与参数反演。
专题一:机器学习分子动力学
上下滑动查看完整内容
第一天
AI4Science时代的分子模拟基石
1.理论内容
1.1 AI for Science与分子模拟新范式
1.1.1 科学研究的四范式演进:从实验、理论、计算到数据驱动
1.1.2 AI for Science (AI4Science) 时代的核心理念与机遇
1.1.3 分子动力学模拟在AI4Science中的角色:从传统经验力场、第一性原理到机器学习力场的跨越
1.2 机器学习力场(ML-FFs)概览
1.2.1 ML-FFs的核心优势:兼顾第一性原理精度与经验力场效率
1.2.2 ML-FFs的基本工作流程:数据生成、模型训练、模型验证、应用模拟
1.2.3 ML-FFs的主要分类、发展历程及关键里程碑
1.3 分子动力学(MD)模拟基础回顾
1.3.1 MD模拟基本原理:系综、积分算法、周期性边界条件、力场
1.3.2 LAMMPS模拟软件介绍:架构、安装、基本使用
1.3.3 LAMMPS输入文件(in script)结构解析:单位、原子类型、力场参数、模拟指令
1.3.4 常见传统力场(如EAM, Lennard-Jones, GAFF)简介及其参数获取
1.4 第一性原理(AIMD)数据生成引言
1.4.1 为何需要第一性原理数据:ML-FF的数据来源
1.4.2 常用量子化学计算软件简介(CP2K, VASP, ORCA):在ML-FF数据生成中的作用(概念性介绍)
1.4.3 简介XTB等半经验方法作为快速数据生成的选项
2.实操内容
2.1 科研计算环境搭建与基础操作
2.1.1 Linux系统常用命令与Shell脚本入门
2.1.2 HPC超算平台使用简介:作业提交、队列管理
2.1.3 Python (Jupyter Notebook/VSCode) 科研环境配置:Anaconda/Mamba虚拟环境管理
2.2 经典MD模拟与数据分析入门
2.2.1 使用LAMMPS运行简单体系(如金属、简单有机分子)的经典MD模拟
2.2.2 MD轨迹数据(dump, log)的基本解读
2.2.3 使用OVITO/VMD进行轨迹可视化
2.2.4 使用Python (MDAnalysis/MDTraj) 进行初步后处理:如能量、温度、压力曲线绘制
第二天
深入DeePMD-kit:从理论到实践
1.理论内容
1.1 机器学习入门与神经网络基础
1.1.1 机器学习核心概念:监督学习、损失函数、梯度下降、过拟合/欠拟合
1.1.2 神经网络:神经元、激活函数、全连接层、反向传播
1.1.3 卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等基本框架简介
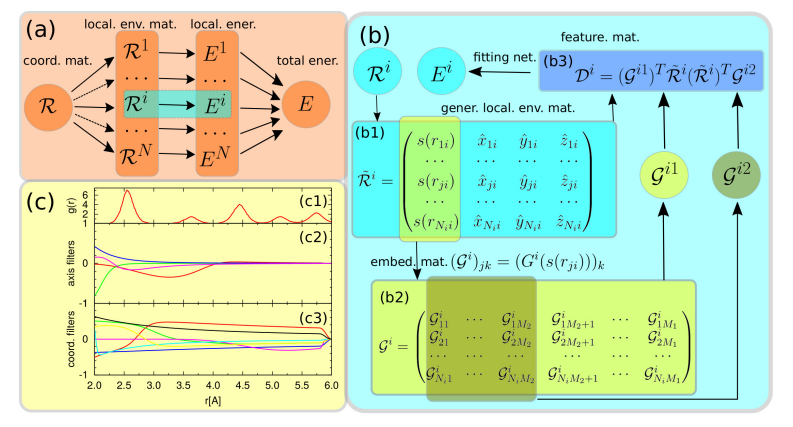
1.2 DeePMD-kit模型详解
1.2.1 基于描述符的ML-FF回顾:Behler-Parrinello神经网络(BPNN)
1.2.2 DeePMD模型架构:特征工程(Descriptor - Smooth Edition, SE)与拟合网络
1.2.3 DeePMD的各种描述符(se_e2_a, se_e2_r, se_e3)特点与选择
1.3 DeePMD-kit模型训练与优化
1.3.1 输入脚本(input.json)详解:模型参数、训练参数、学习率策略
1.3.2 训练过程监控:loss曲线分析、模型验证
1.3.3 模型冻结(freezing)、压缩(compression)原理与应用
1.3.4 常见训练问题与调试技巧
1.4 DP-GEN:多任务、高效率主动学习数据生成
1.4.1 主动学习(Active Learning)在ML-FF中的应用
1.4.2 DP-GEN工作流程:exploration, labeling, training, selection
1.4.3 DP-GEN的输入(param.json, machine.json)与输出文件详解
2.实操内容
2.1 DeePMD-kit环境配置与数据准备
2.1.1 DeePMD-kit的安装(CPU/GPU版本)与依赖(TensorFlow)
2.1.2 训练数据的格式与预处理:能量、力、virial的组织
2.1.3 使用工具将第一性原理计算输出转换为DeePMD训练格式
2.2 DeePMD-kit模型训练、测试及LAMMPS联用
2.2.1 训练一个简单的DeePMD模型(提供示例数据集)
2.2.2 模型测试:力、能量的精度评估与误差分析
2.2.3 将训练好的DeePMD模型(.pb文件)与LAMMPS联用进行MD模拟
2.2.4 DP-GEN的基本配置与运行演示
第三天
等变神经网络力场:NequIP与Allegro
1.理论内容
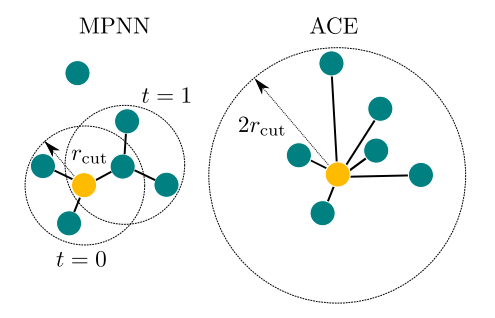
1.1 图神经网络(GNN)与分子表示
1.1.1 图的基本概念与在分子系统中的应用
1.1.2 消息传递神经网络(MPNN)框架
1.1.3 早期基于GNN的力场模型简介(如SchNet)
1.2 等变性(Equivariance)在ML-FF中的核心作用
1.2.1 不变性(Invariance)与等变性(Equivariance)辨析
1.2.2 旋转、平移、置换对称性在物理系统中的重要性
1.2.3 SO(3)/E(3)等变性对数据效率和泛化能力的提升
1.2.4 球谐函数与张量积在构建等变特征中的应用简介
1.3 NequIP模型详解
1.3.1 NequIP (E(3)-Equivariant Neural Network for Interatomic Potentials) 架构
1.3.2 核心组件:等变卷积、张量积的运用
1.3.3 NequIP的优势、局限性及代码框架
1.4 Allegro模型详解
1.4.1 NequIP团队的后续工作:Allegro的动机与改进
1.4.2 基于张量积的局部环境描述符与迭代更新
1.4.3 Allegro在计算效率和可扩展性上的提升
2.实操内容
2.1 等变性概念的直观理解与可视化
2.1.1 Python代码示例:可视化旋转操作对等变/不变特征的影响
2.1.2 E3NN库的简单介绍与使用示例
2.2 NequIP/Allegro模型的初步使用
2.2.1 NequIP/Allegro软件安装与环境配置
2.2.2 使用预训练模型进行预测或运行示例训练
2.2.3 超参数文件(YAML格式)解读与初步调整
第四天
MACE模型:精度、效率与可解释性的探索
1.理论内容
1.1 原子团簇展开(ACE)方法回顾
1.1.1 ACE作为一种系统性的、完备的原子环境描述方法
1.1.2 其与传统描述符和图方法的联系与区别
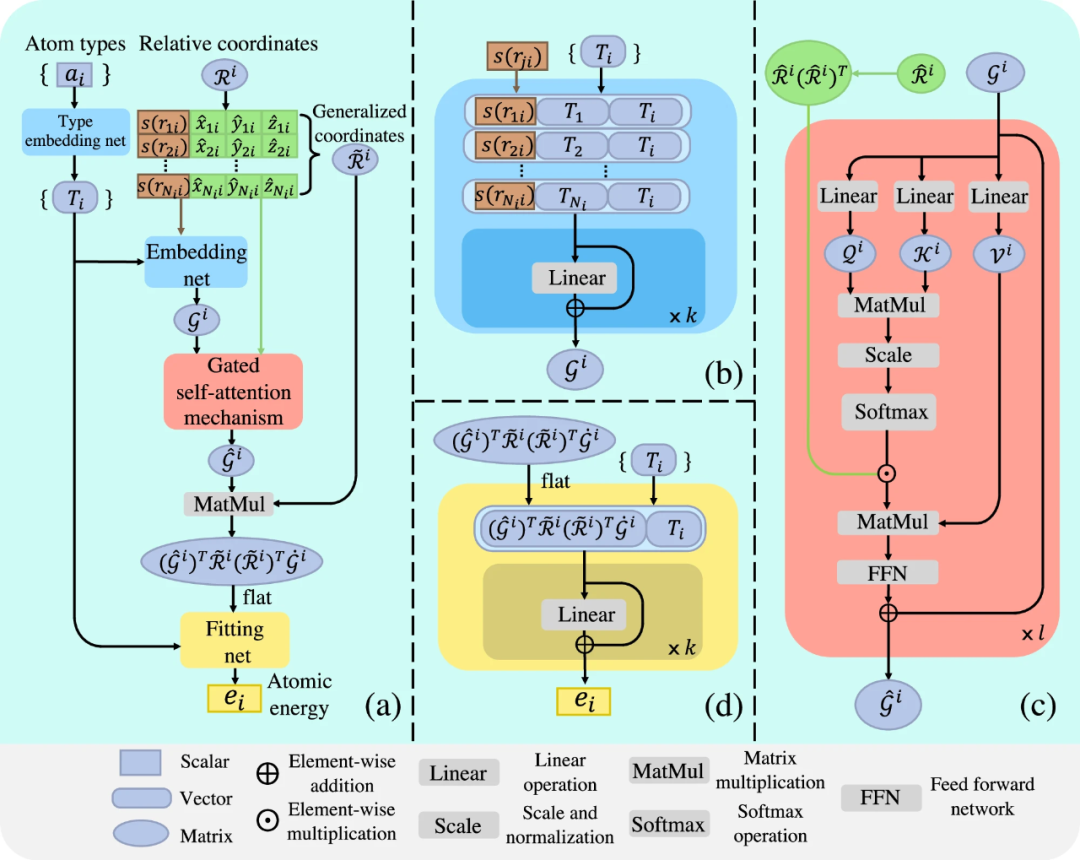
1.2 MACE (Multi-ACE) 模型详解
1.2.1 MACE模型架构:结合ACE的高阶身体项与消息传递框架
1.2.2 等变性在MACE中的实现方式
1.2.3 MACE模型的完备性、数据效率和计算效率分析
1.2.4 MACE在不同体系(有机分子、材料、生物大分子)中的应用案例
1.3 MACE模型训练与超参数调优
1.3.1 MACE训练脚本与关键超参数解读(如r_max, num_interactions, correlation order, hidden_irreps)
1.3.2 训练技巧、收敛性判断与模型验证策略
1.3.3 MACE与DeePMD在数据效率、精度、计算成本上的对比讨论
1.4 Mattersim平台与相关工具生态
1.4.1 Mattersim作为支持MACE等模型开发与应用的平台/工具集介绍
1.4.2 Libtorch在MACE与LAMMPS/其他MD引擎接口中的作用与编译
1.4.3 将训练好的MACE模型导出为TorchScript格式,以便在LAMMPS等软件中使用
2.实操内容
2.1 MACE环境配置与数据准备
2.1.1 MACE软件安装与依赖(PyTorch, e3nn)
2.1.2 训练数据格式要求(如ASE Atoms对象)
2.1.3 将常见数据格式转换为MACE训练所需格式
2.2 MACE模型训练与LAMMPS联用
2.2.1 运行MACE提供的示例训练脚本,分析训练日志与输出
2.2.2编译LAMMPS使其支持TorchScript模型接口
2.2.3 使用训练好的MACE模型通过LAMMPS进行分子动力学模拟
第五天
通用大模型、微调技巧与前沿展望
1.理论内容
1.1 ML-FF领域的预训练大模型
1.1.1 “机器学习力场领域的ChatGPT”:通用大模型的概念与意义
1.1.2 MACE-OFF23:针对有机分子体系的通用力场详解
1.1.3 MACE-MP0:覆盖元素周期表大部分元素的材料领域通用力场详解
1.1.4 DPA-1 (Deep Potential Alchemy) / DPA-2:及其在跨体系、跨元素泛化方面的努力
1.1.5 其他开源大模型简介与获取渠道(如CHGNet等)
1.2 大模型的微调(Fine-tuning)策略与技巧
1.2.1 为何需要微调:提升在特定体系或性质上的表现
1.2.2 微调的数据准备、参数设置与常见技巧
1.3 高级应用与专题
1.3.1 多GPU并行训练ML-FFs的策略与实践(DeePMD, MACE)
1.3.2 ML-FFs在复杂体系(如合金、催化、电池材料、生物大分子)中的应用案例
1.3.3 分子模拟结果的高级后处理与分析:径向分布函数(RDF)、角分布函数(ADF)、扩散系数(MSD)等
1.3.4 使用Python进行高质量科研绘图(Matplotlib, Seaborn)
1.4 ML-FFs的挑战与未来展望
1.4.1 当前ML-FFs面临的挑战:长程相互作用、反应模拟、可解释性、数据稀疏区域的泛化等
1.4.2 结合多尺度建模、强化学习、AI生成模型等方向的未来趋势
2.实操内容
2.1 使用与微调预训练MACE模型
2.1.1 下载并使用MACE-OFF23/MACE-MP0进行特定体系的能量/力预测
2.1.2演示对预训练MACE模型进行微调的过程
2.1.3 对比微调前后模型在特定任务上的表现
2.2 模拟结果分析与绘图
2.2.1 使用MDAnalysis等工具分析LAMMPS+MLFF模拟轨迹
2.2.2 计算并绘制能量、力预测曲线,径向分布函数,键长/键角分布等
专题二:深度学习第一性原理
上下滑动查看完整内容
专题三:人工智能辅助材料设计
上下滑动查看完整内容
第一天:材料机器学习基础与Python环境配置
第一天将系统讲解机器学习在材料科学中的应用背景与Python编程基础。分为如下几个部分:首先概述机器学习在材料与化学领域的核心价值,涵盖材料发现、性能预测等应用场景;其次将指导学员完成Vscode、Anaconda开发环境搭建,通过变量定义、控制流语句等基础语法教学,掌握函数封装、类与对象构建及模块化编程的进阶技巧;最后聚焦科学数据处理工具链,系统学习NumPy矩阵运算、Pandas数据分析、Matplotlib/Seaborn可视化技术及文件系统操作,为材料数据建模奠定工程基础。
【理论内容】
1.机器学习概述
2.材料与化学中的常见机器学习方法
3.应用前沿
【实操内容】
1.Python基础
1)开发环境搭建
2)变量和数据类型
3)控制流
2.Python基础(续)
1)函数
2)类和对象
3)模块
3.Python科学数据处理
1)NumPy
2)Pandas
3)绘图可视化
4)文件系统
第二天:材料机器学习基础算法与催化活性预测实战
第二天将深入解析初级机器学习算法的数学原理及其在材料科学中的典型应用场景。分为如下几个部分:首先系统讲解线性模型家族的理论体系,从线性回归的解析解推导、逻辑回归的交叉熵损失函数,拓展到Softmax回归在多分类任务中的概率建模机制,着重分析激活函数在非线性映射中的关键作用;接着引入感知机模型作为神经网络的基础原型,通过回归与分类任务的对比,揭示机器学习算法中最核心的两类任务的区别。最后以CO2催化活性预测为切入点,在解析催化活性与电子结构特征的关联规律中,完整演练材料机器学习项目的标准流程:使用金属氧化物催化剂数据集,结合Scikit-learn库实现数据标准化处理、特征工程构建、模型选择、超参数网格搜索与ROC曲线评估。
【理论内容】
1.线性回归
1)线性回归的原理
2)线性回归的应用
2.逻辑回归
1)逻辑回归的原理
2)逻辑回归的应用
3.Softmax回归
1)Softmax回归的原理
2)Softmax回归的应用
4.感知机(浅层神经网络)
1)感知机的原理
2)使用感知机进行回归
3)使用感知机进行分类
【项目实操内容】
1.机器学习对CO2催化活性的预测|机器学习入门简单案例
1)机器学习材料与化学应用的典型步骤
a)数据采集和清洗
b)特征选择和模型选择
c)模型训练和测试
d)模型性能评估和优化
2)sklearn库介绍
a)sklearn库的基本用法
b)sklearn库的算法API
c)sklearn库的模型性能评估

第三天:材料机器学习进阶算法与项目实战
第三天将系统剖析机器学习中的进阶算法的数学框架及其在材料复杂体系中的建模策略。分为如下几个部分:首先从决策树的信息增益分裂准则切入,对比ID3/C4.5/CART算法的特征选择差异,并引申至集成学习框架中Bagging(随机森林)与Boosting(XGBoost)对模型偏差-方差权衡的优化机制;接着解析朴素贝叶斯基于特征条件独立假设的概率建模方法,及其在材料高通量筛选中的计算效率优势;最后深入探讨支持向量机的核函数映射技巧,通过可视化手段对比线性核、多项式核与高斯核在材料相态分类任务中的决策边界差异。
实战环节聚焦材料多尺度特性预测:在双金属ORR催化活性预测项目中,通过构建合金组分-电子结构特征矩阵,运用随机森林的变量重要性分析筛选关键描述符,结合Adaboost算法提升预测精度;在高熵合金相态分类任务中,基于原子半径、电负性等特征,演示支持向量机如何通过核函数变换处理非线性可分数据,并可视化决策超平面;同时拓展至生物炭材料回归预测,利用支持向量回归(SVR)分析孔隙率-吸附性能的定量关系。课程将结合Scikit-learn工具链,贯穿特征标准化、交叉验证、混淆矩阵评估等工业级实践流程。
【理论内容】
1.决策树
1)决策树的原理
2)决策树的应用
2.集成学习
1)集成学习的原理
2)集成学习的方法和应用
3.朴素贝叶斯
1)朴素贝叶斯的原理
2)朴素贝叶斯的应用
4.支持向量机
1)支持向量机的原理
2)支持向量机的应用
【项目实操内容】
1.利用集成学习预测双金属ORR催化剂活性
1)Sklearn中的集成学习算法
2)双金属ORR催化活性预测实战
a)数据集准备
b)特征筛选
c)模型训练
d)模型参数优化
2.使用支持向量机预测高熵合金相态
1)支持向量机的可视化演示
a)绘制决策边界
b)查看不同核函数的区别
2)支持向量机预测高熵合金相态(分类)
a)数据集准备
b)数据预处理
c)特征工程
d)模型训练及预测
3)支持向量机预测生物炭材料废水处理性能(回归)
a)数据集准备
b)数据预处理
c)模型训练及预测
第四天:材料无监督学习与分子特征工程实践
第四天将系统构建材料数据表征体系与无监督分析技术栈。分为如下几个部分:首先解析无监督学习的核心范式,对比K-Means聚类与DBSCAN密度聚类在材料相组成识别中的差异,详解常用的无监督学习技术在材料高通量筛选中的可视化应用;接着深入探讨材料特征工程的数学表达方法;最后结合Materials Project、COD等材料数据库,演示通过Pymatgen工具包自动化获取晶体能带结构、弹性张量等关键性质数据。
实战环节聚焦材料多模态数据处理:在石墨烯样品表征任务中,通过处理二维电镜图像,运用无监督聚类算法实现样品质量分级;针对高能材料分子性质预测,构建从SMILES字符串到3D分子坐标的全流程特征工程:使用RDKit生成初始构型,通过ASE优化分子结构,计算库伦矩阵与原子极化张量作为量子化学特征,对比Morgan指纹与MACCS键合描述符对机器学习模型性能的影响。
【理论内容】
1.无监督学习
1)什么是无监督学习
2)无监督学习算法-聚类
3)无监督学习算法-降维
2.材料与化学数据的特征工程
1)分子结构表示
2)晶体结构表示
3.数据库
1)材料数据库介绍
2)Pymatgen介绍
【项目实操内容】
1.无监督学习在材料表征中应用
1)K-Means聚类算法
2)石墨烯样品数据集准备
3)二维电镜图像处理
4)聚类及统计
2.利用机器学习预测高能材料分子性质
1)高能分子数据集准备
2)从SMILES生成分子坐标
3)从分子坐标计算库伦矩阵
4)测试不同分子指纹方法
5)比较不同特征化方法
6)模型性能评估
第五天:材料机器学习项目实践专题
第五天将深度融合前沿模型技术与材料多尺度特性预测场景。分为如下几个部分:首先系统解析大语言模型在材料研究中的创新应用范式,重点讲解DeepSeek的transformer架构原理及其在材料文献挖掘、实验方案生成等场景的提示词工程技巧;接着深入探讨更多的材料机器学习的常见技术路径,比如通过决策树的特征分裂可视化与SHAP值分析,揭示材料性能与微观结构的内在关联规律;最后为构建深度学习技术栈打基础,对比PyTorch动态计算图与Scikit-learn静态架构在复杂材料建模中的工程差异。
【项目实操内容】
1. DeepSeek提示词工程和落地场景
1)DeepSeek简介
2)大语言模型和DeepSeek原理
3)DeepSeek提示词工程和落地场景
2.利用机器学习加速发现耐高温氧化的合金材料
4)合金材料数据集准备
5)数据预处理
6)特征构建和特征分析
7)多种模型训练
8)使用训练好的模型进行推理
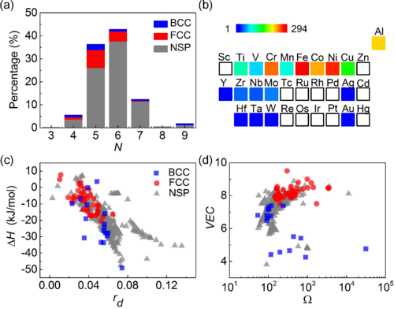
3.决策树(可解释性机器学习)预测AB2合金的储氢性能
1)储氢合金材料数据集准备
2)决策树基本流程
3)动手建立一棵树
4)决策树剪枝
5)决策过程可视化和特征重要性分析
6)分类决策树和回归决策树的区别
4.分子渗透性分类预测
7)使用定量的1D分子描述符和不同的机器学习模型进行QSAR模型的训练和预测
8)使用定性的2D分子描述符和不同的机器学习模型进行QSAR模型的训练和预测
9)比较不同分子描述方法对QSAR模型性能的影响
5.多层感知机预测单晶合金晶格错配度
1)PyTorch与Scikit-learn中多层感知机的区别
2)使用PyTorch构建多层感知机
3)训练PyTorch多层感知机模型预测单晶合金晶格错配度
4)PyTorch多层感知机模型参数优化

专题四:人工智能助力结构力学应用与仿真
上下滑动查看完整内容
第一天:机器学习与Python结构力学基础
目标:掌握结构力学基础、Python编程在结构力学中的应用,以及机器学习的基本概念,为后续深度学习与有限元结合奠定基础。
1.结构力学基础
理论:结构力学基本概念(静力平衡、应力-应变关系、刚度矩阵)。
1.1静力学基本方程:平衡方程、应力-应变关系和本构方程,结合胡克定律。
1.2刚度矩阵推导:讲解杆单元刚度矩阵的构建过程,分析局部与全局坐标系转换。
1.3边界条件处理:探讨固定支座、铰支座和滑动支座的数学表达。
*工具:Python实现矩阵位移法和直接刚度法。
1.4 NumPy矩阵运算:使用NumPy实现刚度矩阵组装,优化计算效率。
1.5单元类型扩展:引入梁单元和板单元的刚度矩阵。
1.6可视化工具:使用Matplotlib绘制结构变形和内力分布。
*实操:使用基于python的计算结构力学示例代码,分析简单梁受力问题。
1.7梁受均布载荷分析:计算单跨梁的位移和内力,验证解析解。
1.8多材料问题:模拟复合材料梁的受力行为,分析材料参数影响。
1.9误差分析:比较数值解与理论解,探讨网格密度对精度的影响。
2.Python/matlab在结构力学中的应用
理论:Python处理结构力学问题的优势(数值计算、矩阵运算)。
2.1 Python数值计算优势:对比Python与MATLAB在结构力学中的性能。
2.2面向对象编程:讲解如何用类封装单元和节点,提高代码复用性。
2.3并行计算简介:介绍Python多线程在大型结构分析中的应用。
*实操:使用python/matlab结构力学基础示例,编写2D框架结构的有限元求解器。
2.4 2D框架建模:实现平面框架的有限元分析计算节点位移。
2.5动态加载分析:模拟框架受周期性载荷的响应,绘制时间-位移曲线。
2.6自动化脚本:编写脚本批量处理不同几何和载荷条件。
2.7模态分析:基于matlab用于结构力学应用的线性FEM求解器的Python实现,计算结构自振频率。
2.8图形用户界面:使用PyQt或Tkinter开发简单的结构分析GUI。
2.9单元测试:编写单元测试验证刚度矩阵和位移解的正确性。
*3.机器学习基础
理论:机器学习基本概念(监督学习、无监督学习、深度学习神经网络)。
3.1监督学习算法:讲解线性回归、支持向量机在结构力学中的应用。
3.2无监督学习:介绍主成分分析(PCA)在结构数据降维中的作用。
3.3 机器学习(监督学习、无监督学习、深度学习神经网络)项目案例实操
3.4 神经网络结构:剖析前馈神经网络的层次设计和反向传播原理。
*实操:基于人工神经网络在结构力学中的应用项目
3.4数据集生成:使用有限元模拟生成梁位移数据集,包含不同载荷和边界条件。
3.5模型训练:使用TensorFlow/PyTorch实现三层神经网络,预测梁的最大位移。
3.6性能评估:计算均方误差(MSE)和R²,分析模型预测精度。
3.7超参数调优:调整学习率和隐藏层节点数,优化模型性能。
3.8数据增强:通过随机扰动生成更多训练样本,提高模型泛化能力。
3.9可视化预测:使用Seaborn绘制预测值与真实值的对比图。
第二天:PINN模型在结构力学中的应用
目标:理解物理信息神经网络(PINN)原理,学习其在结构力学偏微分方程求解中的应用。
1.PINN基础
理论:PINN结合物理方程与神经网络的原理。
1.1 PINN数学框架:讲解PINN如何将PDE残差融入损失函数。
1.2优势与局限性:对比PINN与传统有限元的计算效率和精度。
1.3应用场景:分析PINN在弹性力学、热传导中的适用性。
*实操:基于用于结构力学的物理信息神经网络PINNs,实现弹性力学问题的PINN求解。
1.4 2D弹性问题:实现平面应力问题的PINN求解,验证位移场。
1.5边界条件嵌入:将Dirichlet和Neumann边界条件融入PINN模型。
1.6损失函数分析:可视化PDE残差和边界条件损失的收敛曲线。
1.7网格无关性:测试PINN在不同采样点密度下的性能。
1.8多物理场耦合:扩展PINN模型,模拟热-结构耦合问题。
1.9模型对比:与FEniCS求解结果对比,分析PINN的优劣。
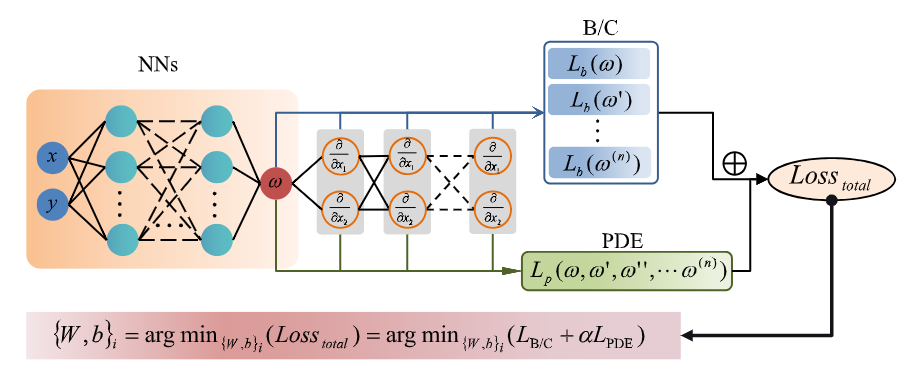
*2.PINN在结构力学中的应用
理论:PINN解决静力学、动力学问题。
2.1静力学应用:讲解PINN如何求解PDE方程。
2.2动力学问题:分析PINN在振动分析中的潜力。
2.3非线性问题:探讨PINN处理几何非线性和材料非线性的能力。
*实操:使用PyTorch实现2D板受力问题的PINN模型,验证结果与传统有限元对比。
2.4板受集中力:模拟矩形板受集中载荷的变形。
2.5时间依赖问题:实现瞬态动力学问题的PINN求解。
2.6结果可视化:绘制应力场和位移场,比较PINN与FEA结果。
2.7参数化建模:实现不同材料参数下的PINN预测。
2.8高维问题:尝试3D弹性问题的PINN求解,分析计算成本。
2.9噪声鲁棒性:在输入数据中加入噪声,测试PINN的稳定性。
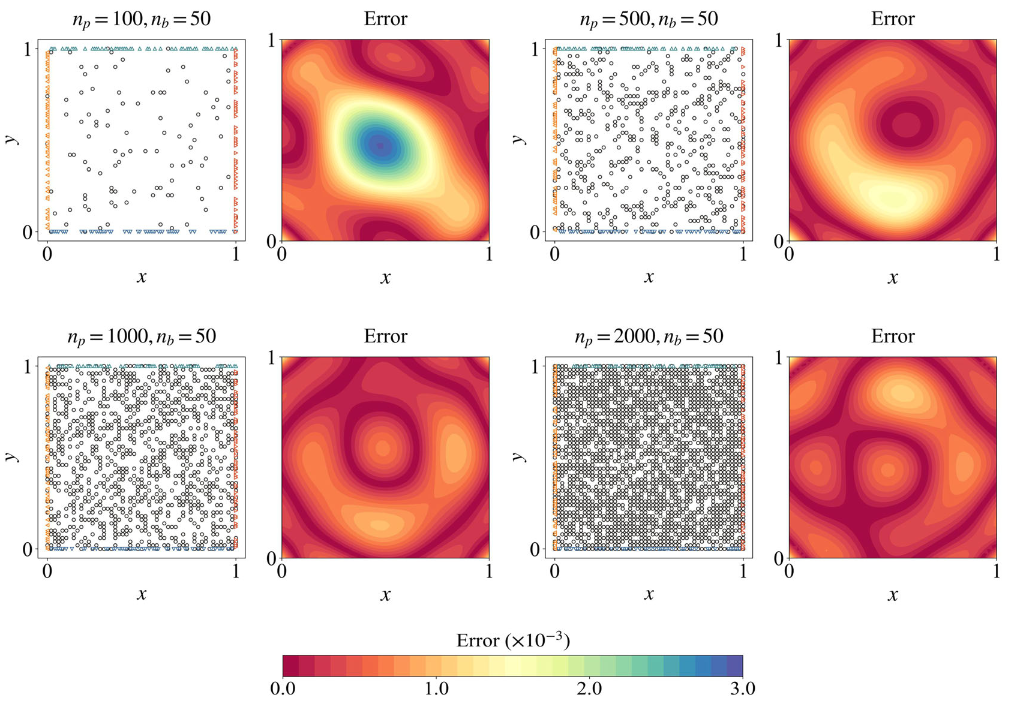
*3.数据预处理与模型优化
理论:PINN训练中的数据归一化、损失函数设计。
3.1数据归一化:讲解归一化对PINN收敛性的影响。
3.2损失函数设计:分析PDE损失、边界损失和初始条件损失的权重分配。
3.3正则化技术:介绍L2正则化和Dropout在PINN中的应用。
*实操:基于有限元信息神经网络,优化PINN模型,处理复杂边界条件。
3.4数据清洗:去除仿真数据中的异常值,确保训练稳定性。
3.5超参数调优:调整学习率和网络层数,优化模型性能。
3.6交叉验证:使用k折交叉验证评估PINN的泛化能力。
3.7自适应采样:实现基于残差的自适应采样点生成。
3.8批量训练:优化批量大小,加速PINN训练过程。
3.9损失分析:绘制各部分损失随epoch变化的曲线,诊断模型问题。
*4.DeepSeek优化PINN
理论:DeepSeek在PINN超参数调优中的作用。
4.1自动化调参:讲解DeepSeek如何生成超参数组合。
4.2代码优化:分析DeepSeek在重构PINN代码中的潜力。
4.3模型解释:探讨DeepSeek生成PINN模型解释文档的可能性。
*实操:使用DeepSeek生成PINN训练脚本,分析其效率提升。
4.4脚本生成:生成PyTorch实现的PINN训练代码。
4.5性能测试:比较DeepSeek生成代码与手动编写的运行时间。
4.6错误修正:使用DeepSeek修复PINN训练中的收敛问题。
4.7网络架构优化:使用DeepSeek设计更深的PINN网络。
4.8数据生成:生成模拟训练数据,扩充PINN数据集。
4.9可视化辅助:生成PINN结果的可视化脚本,绘制3D应力场。

第三天:ABAQUS结构力学仿真及其仿真实验数据在机器学习中的应用
目标:掌握ABAQUS进行结构力学仿真的流程,学习如何将仿真数据应用于机器学习模型。
1.ABAQUS结构力学仿真基础
理论:ABAQUS建模流程(几何、网格、材料、边界条件)。
1.1几何建模:讲解复杂几何的导入与简化方法。
1.2网格划分:分析结构化与非结构化网格对精度的影响。
1.3材料模型:介绍线性弹性与弹塑性材料的定义。
*实操:使用ABAQUS模拟有限元结构受力仿真分析
*2.仿真数据提取与预处理
理论:从ABAQUS提取位移、应力等数据,数据清洗与归一化。
2.1ODB文件结构:讲解ABAQUS输出数据库(ODB)的组织方式。
2.2数据清洗:处理缺失值和异常值的方法。
2.3特征选择:选择关键特征(如最大应力、位移)用于机器学习。
*实操:使用Python脚本处理ABAQUS输出的ODB文件。
2.4数据提取:编写脚本提取节点位移和单元应力。
2.5数据归一化:使用MinMaxScaler标准化数据。
2.6数据可视化:绘制应力分布的热力图。
2.7数据压缩:使用PCA降维,减少数据维度。
2.8时间序列处理:处理动态仿真的时间依赖数据。
2.9数据增强:通过插值生成更多仿真样本。
*3.机器学习与ABAQUS数据结合
理论:CNN、GAN在处理仿真数据中的应用。
3.1 CNN原理:讲解卷积神经网络在应力场预测中的优势。
3.2 GAN应用:分析生成对抗网络在数据增强中的作用。
3.3 迁移学习:探讨预训练模型在结构力学中的应用。
*实操:基于基于卷积神经网络的结构力学运动学分析
使用TensorFlow训练CNN预测ABAQUS应力分布。
3.4 CNN建模:构建3层CNN,输入网格化应力数据。
3.5模型训练:使用ABAQUS数据训练CNN,预测最大应力位置。
3.6结果对比:比较CNN预测与ABAQUS结果的误差。
3.7GAN数据生成:使用GAN生成仿真应力场,扩充训练集。
3.8模型解释:使用SHAP分析CNN对特征的敏感性。
3.9实时预测:实现CNN对新仿真数据的实时预测。
*4.DeepSeek辅助ABAQUS二次开发
理论:DeepSeek生成ABAQUS Python脚本。
4.1 UMAT开发:讲解用户材料子程序的编写流程。
4.2自动化脚本:分析DeepSeek在生成前处理脚本中的作用。
4.3参数优化:探讨DeepSeek在材料参数识别中的应用。
*实操:使用DeepSeek优化ABAQUS材料模型,验证其准确性。
4.4UMAT生成:生成弹塑性材料的UMAT代码。
4.5脚本调试:使用DeepSeek修复UMAT中的收敛问题。
4.6仿真验证:运行ABAQUS验证优化后的材料模型。
4.7网格优化:生成脚本自动调整网格密度。
4.8后处理自动化:生成脚本批量提取仿真结果。
4.9错误日志分析:使用DeepSeek解析ABAQUS报错信息。
第四天:COMSOL结构力学仿真及其仿真实验数据在机器学习中的应用
目标:学习COMSOL进行结构力学仿真的方法,探索仿真数据与机器学习结合的应用。
1.COMSOL结构力学仿真基础
理论:COMSOL多物理场建模流程,结构力学模块设置。
1.1多物理场耦合:讲解热-结构、流-结构耦合的建模方法。
1.2网格类型:分析自适应网格与手动网格的优劣。
1.3求解器选择:比较直接求解器与迭代求解器的适用场景。
*实操:使用COMSOL模拟受力问题,导出位移和应力数据。
1.4建模:创建3D模型,设置车辆载荷。
1.5仿真设置:配置边界条件和材料属性。
1.6数据导出:导出位移和应力场数据。
1.7模态分析:计算自振频率和振型。
1.8参数化扫描:分析不同载荷下的响应。
1.9优化设计:使用COMSOL优化模块调整几何。
*2.COMSOL数据预处理
理论:COMSOL数据格式与特征提取。
2.1数据格式解析:讲解COMSOL输出文件的结构。
2.2特征工程:提取关键特征(如最大应变能密度)。
2.3数据标准化:分析标准化的必要性和方法。
*实操:基于评估结构力学实验数据(压力和挠度)的方法,编写Python脚本处理COMSOL输出数据。
2.4数据提取:提取节点的位移和应力数据。
2.5数据清洗:去除噪声和冗余数据。
2.6数据可视化:绘制应力分布的3D图。
2.7数据插值:使用SciPy插值生成高分辨率数据。
2.8数据分割:划分训练集和测试集,准备机器学习。
2.9异常检测:使用孤立森林算法识别数据异常点。
*3.机器学习与COMSOL数据结合
理论:变分自编码器(VAE)在仿真数据分析中的应用。
3.1 VAE原理:讲解VAE在数据生成和特征提取中的作用。
3.2聚类分析:分析VAE在仿真数据聚类中的应用。
3.3模型选择:比较VAE与传统机器学习模型的性能。
*实操:使用PyTorch训练VAE模型,分析COMSOL仿真数据中的潜在特征。
3.4 VAE建模:构建VAE模型,输入桥梁应力数据。
3.5特征提取:提取潜在空间特征,分析数据分布。
3.6重构分析:比较VAE重构数据与原始数据的误差。
3.7数据生成:使用VAE生成新的仿真样本。
3.8降维可视化:使用t-SNE可视化潜在特征。
3.9模型优化:调整VAE的网络结构,提升重构精度。
*4.DeepSeek优化COMSOL流程
理论:DeepSeek生成COMSOL脚本或优化模型参数。
4.1 COMSOLPython接口。
4.2自动化建模:分析DeepSeek在生成建模脚本中的作用。
4.3参数优化:探讨DeepSeek在优化仿真参数中的潜力。
*实操:使用DeepSeek生成COMSOLPython接口代码,自动化仿真流程。
4.4脚本生成:生成桥梁仿真的COMSOL脚本。
4.5仿真自动化:实现多组载荷条件的批量仿真。
4.6结果验证:比较DeepSeek生成脚本与手动仿真的结果。
4.7网格优化:生成脚本自动调整COMSOL网格。
4.8后处理脚本:生成脚本批量处理仿真结果。
4.9错误分析:使用DeepSeek解析COMSOL仿真错误日志。
第五天:机器学习结构力学科研论文复现及其项目剖析
目标:复现机器学习与结构力学结合的科研论文,剖析综合项目,展望未来研究方向。
1.论文复现:PINN与有限元结合
理论:精读计算力学中的深度学习综述,理解PINN与FEA的集成方法。
1.1 PINN与FEA集成:分析PINN如何增强有限元精度。
1.2案例分析:讲解论文中的典型应用场景(如梁弯曲问题)。
1.3研究趋势:探讨PINN在多尺度建模中的潜力。
*实操:基于有限元信息神经网络(升级版),复现论文中的静态问题求解案例。
1.4FEINN建模:实现2D梁的静态分析。
1.5结果验证:比较FEINN与传统FEA的位移和应力结果。
1.6可视化:绘制FEINN预测的应力场。
1.7参数敏感性:分析材料参数对FEINN预测的影响。
1.8复杂几何:复现论文中的复杂几何案例。
1.9模型扩展:尝试将FEINN应用于非线性问题。
*2.综合项目剖析
1.论文剖析与复现
1.1 论文研读
1.2 论文复现
1.3 算法优化与创新点加持
*实操:使用用于在FEniCS中模拟静态准静态结构力学问题
2.结合基于卷积神经网络的结构力学运动学分析CNN模型优化设计。
2.4网格生成:使用FEniCS生成有限元网格。
2.5 CNN优化:训练CNN预测应力分布,优化几何参数。
2.6结果评估:比较优化前后性能指标。
2.7多目标优化:使用NSGA-II算法实现重量和强度的多目标优化。
2.8动态响应:分析振动载荷下的响应。
2.9报告生成:编写项目报告,总结优化结果。
*3.前沿技术与未来方向
理论:探讨低秩张量分解和图神经网络在结构力学中的潜力。
3.1低秩张量分解:讲解LRTD在高维数据压缩中的应用。
3.2图神经网络:分析GNN在网格化数据建模中的优势。
3.3未来趋势:探讨量子计算和AI在结构力学中的潜力。
*实操:尝试基于解决结构力学问题的深度学习方法,实现简单图神经网络预测结构响应。
3.4 GNN建模:构建GNN模型,预测梁的位移。
3.5训练与验证:训练GNN,验证预测精度。
3.6结果分析:比较GNN与CNN的性能。
3.7 LRTD应用:使用LRTD压缩仿真数据,加速GNN训练。
3.8多尺度建模:尝试GNN在多尺度结构分析中的应用。
3.9文献调研:搜索最新GNN相关论文,总结应用场景。
*4.DeepSeek辅助科研
理论:DeepSeek在论文写作和代码调试中的作用。
4.1论文写作:讲解DeepSeek生成LaTeX论文框架的优势。
4.2代码调试:分析DeepSeek在优化算法中的作用。
4.3数据分析:探讨DeepSeek在处理实验数据中的潜力。
*实操:使用DeepSeek生成论文LaTeX模板或优化复现代码。
4.4 LaTeX生成:生成论文引言和方法部分的LaTeX代码。
4.5代码优化:优化FEINN代码,减少训练时间。
4.6结果总结:生成实验结果的总结报告。
4.7参考文献管理:使用DeepSeek生成BibTeX格式的参考文献。
4.8数据可视化:生成实验数据的可视化脚本。
4.9同行评审:模拟DeepSeek生成论文评审意见,改进写作。
专题五:人工智能高性能计算偏微分方程及其应用
上下滑动查看完整内容


01
往期学员反馈
02
课程模式
1、线上授课时间和地点自由,建立专业课程群进行实时答疑解惑。
2、理论+实操授课方式,由浅入深式讲解,结合大量实战案例与项目演练,聚焦人工智能技术在第一性原理、电解质、催化剂领域的最新研究进展。
3、课前发送全部学习资料(上课所有使用的软件、包括丰富的PPT,大量的代码数据集资源)课程提供全程答疑解惑。
4、定期更新的前沿案例,由浅入深式讲解,课后提供无限次回放视频,免费赠送二次学习,永不解散的课程群答疑服务,可以与相同领域内的老师同学互动交流问题,让求知的路上不再孤单!
03
增值服务
1、凡参加人员将获得本次课程学习资料及所有案例模型文件;
2、课程结束可获得本次所学专题全部回放视频;
3、课程会定期更新前沿内容,参加本次课程的学员可免费参加一次本单位后期举办的相同专题课程(任意一期)
01
机器学习分子动力学
2025.8.16-----2025.8.17 (上午9:00-11:30下午13:30-17:00)
2025.8.21-----2025.8.22 (晚上19:00-22:00)
2025.8.23-----2025.8.24 (上午9:00-11:30下午13:30-17:00)
腾讯会议 线上授课(共五天课程 提供全程视频回放及课程群答疑)
02
深度学习第一性原理专题
03
人工智能辅助材料设计
04
人工智能助力结构力学应用与仿真专题
05
人工智能高性能计算偏微分方程及其应用专题
01
报名费用
以上费用包含:
1.课程回放无限次观看
2.学员答疑群
3.免费参加下期本专题内容
4.课程资料(软件,PPT,文件)
02
费用优惠
优惠1:报名成功后转发朋友圈或50人以上群聊即可优惠300元
优惠2:报二赠一
同时报两个专题价格为9080元(免费赠送一个专题,赠送专题任选)
同时报三个专题价格为12880元
参加一年专题课程价格为16880元(一年内所举办的所有专题免费参加)
优惠3:报名任意专题即送往期一门专题回放(包含全部回放,全部资料)
报名费用可开具正规报销发票及提供相关缴费证明、邀请函,可提前开具报销发票、文件用于报销
03
联系方式

联系人:张老师
咨询电话:13141346157(微信同号)
免责声明:本网站所转载的文字、图片与视频资料版权归原创作者所有,如果涉及侵权,请第一时间联系本网删除。

官方微信
《腐蚀与防护网电子期刊》征订启事
- 投稿联系:编辑部
- 电话:010-62316606
- 邮箱:fsfhzy666@163.com
- 腐蚀与防护网官方QQ群:140808414

“海洋金属”——钛合金在舰船的

腐蚀与“海上丝绸之路”