
全面解读材料腐蚀数据的十种挖掘方法
2023-06-01 14:18:31
作者:覃艳民,李辛庚等 来源:腐蚀与防护
分享至:


腐蚀是材料失效的主要途径之一,每年因腐蚀引起的材料损伤、设备失效、安全事故导致了重大的经济损失甚至人身伤亡。因服役环境不同,材料的腐蚀机理、腐蚀行为规律差异很大,对腐蚀行为进行预测也异常困难。为深刻揭示环境因素对材料腐蚀作用的机理与材料腐蚀的演化规律、搜索隐藏于数据中的腐蚀信息,人们依靠信息技术和计算机技术逐步改进了材料腐蚀数据分析方法,发展了一系列腐蚀数据分析模型。 ————————»»»»
早期进行腐蚀数据研究时,腐蚀数据主要来源于挂片腐蚀试验,试验的时间跨度较长,腐蚀数据通常具有高维度、小样本、多层次、高噪声等特征,人们主要基于曲线拟合、多元线性回归分析等传统的数学分析方法,构建材料腐蚀特征参数与环境特征参数之间的数学映射关系,研究环境特征参数对材料腐蚀过程的影响,并通过腐蚀特征参数与环境特征参数之间的定量关系来预测特定环境中的腐蚀演化。 传统的分析方法难以诠释多重环境特征因素对腐蚀的耦合影响,导致基于量化关系预测的腐蚀数据在相对较宽的地域与时域范围内出现较大的偏差。随着腐蚀监检测技术的快速发展,腐蚀数据与部分环境因素数据实现了在线连续采集,并且随着现代数据分析理论的发展,很多新方法被应用于腐蚀数据的挖掘和分析,如神经网络、决策树、随机森林、聚类分析、图像处理等,在处理复杂环境中的腐蚀分析与预测时,这些模型取得了长足的进步。 随着多维度腐蚀大数据的积累,基于多种算法的集成算法被引入腐蚀数据挖掘的机器学习模型中,集成算法可以更好地满足腐蚀数据形式多样化的需求,并提升预测结果的准确度。
1
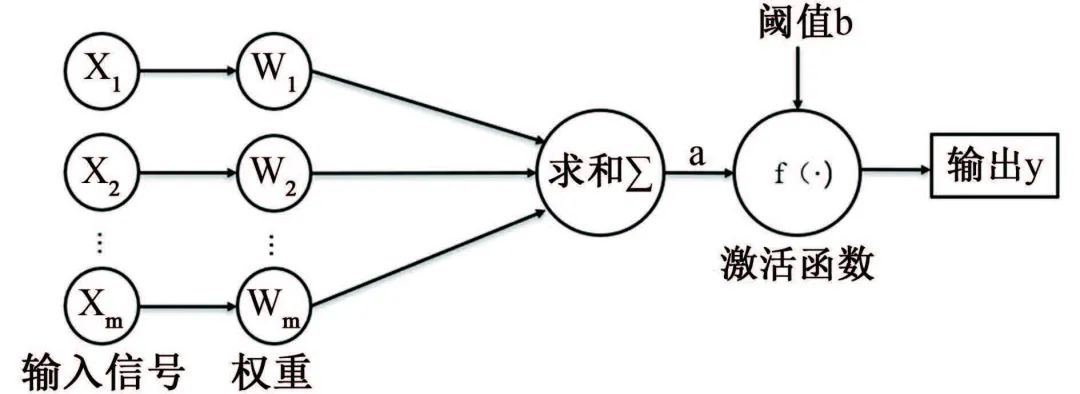
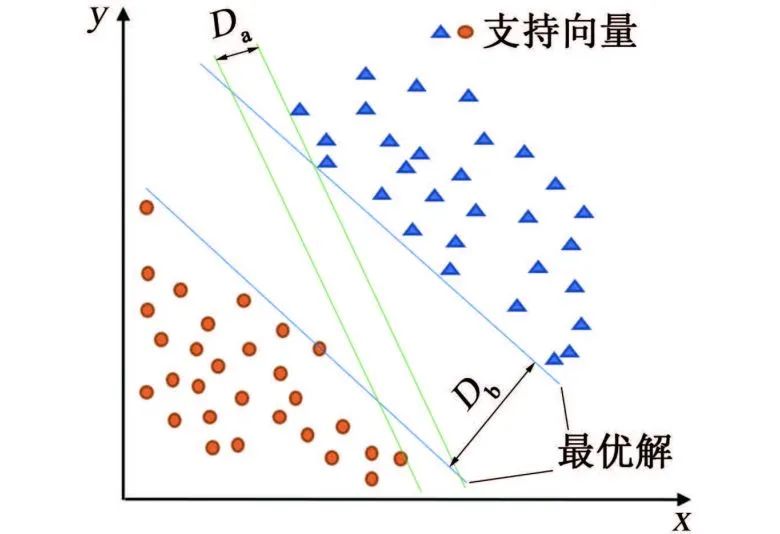
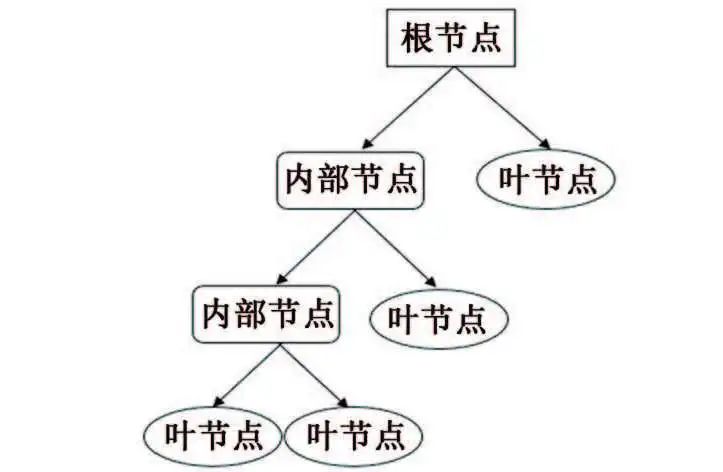
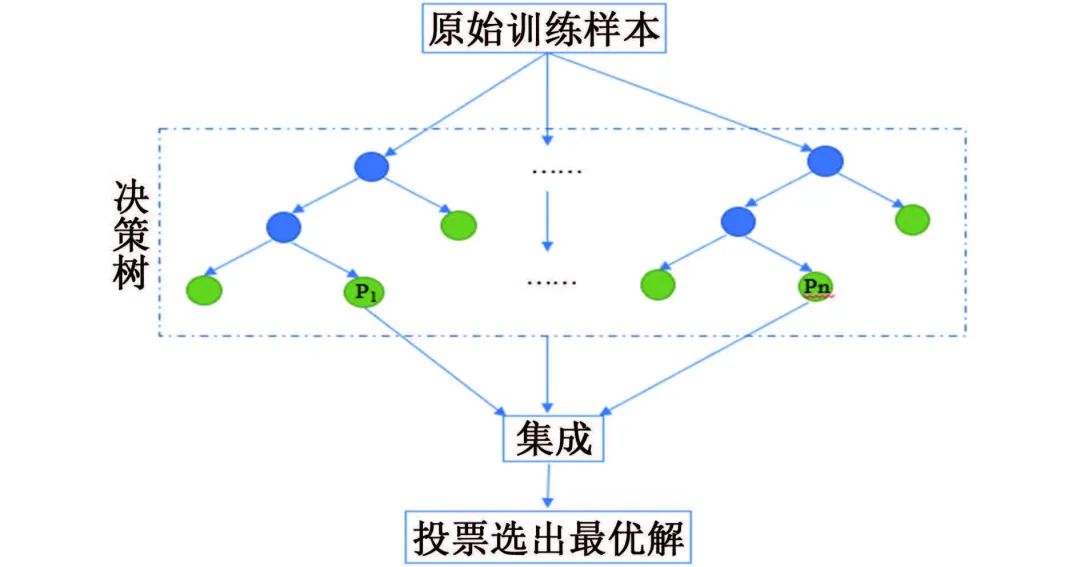
数据挖掘方法 ❤ 数据挖掘兴起于1989年,狭义来说是“数据库知识发现”(KDD)中的一个分析步骤。广义来说,由于KDD各个环节紧密相连,各环节对数据挖掘结果影响很大,数据挖掘往往包含KDD全过程。 如图1所示,KDD是使用统计学、机器学习、数学或人工智能技术等方法从给定数据集中提取有意义数据的过程,可以理解为对大量数据进行分析,以获取潜在有用信息的过程,其技术主要包括:数据的分组、预测、数据的异常记录、数据间的关联法则、序列模式的发现等。 图1 KDD流程图 材料腐蚀研究是一项严重依赖数据的研究,人类自研究腐蚀行为开始,就非常重视腐蚀数据的获取和积累,并试图从中发现或验证相关规律。科学家将腐蚀研究与快速发展的信息科技相结合,形成的材料腐蚀信息学促进了材料腐蚀学的快速发展,为腐蚀分析提供了更多的可能与方法。 2015年,李晓刚等首次提出了“腐蚀大数据”的概念,更加完善了腐蚀信息学的内涵。如何在腐蚀研究中合理利用数据,选择合适的数学挖掘方法和信息化手段成为了材料腐蚀研究的热点之一。 01 多元线性回归方程模型 多元线性回归方程模型被广泛应用于腐蚀预测的研究中,也是最早用于预测环境对材料腐蚀影响的数据挖掘方法。 该方法可以自动从众多变量中选择重要变量并建立回归方程,排除对输出变量影响不显著的变量,形成最优“方程”。研究者通常将监测的气象因子(相对湿度、温度、降水、日照等)和污染物因子(SO2、Cl-、NOx、NH3等)作为一系列的变量与相应的腐蚀率进行回归分析。 早在1960年,日本一研究小组就在日本境内的七个地方开启了为期5年的大气曝晒试验,利用多元线性分析方法处理了曝晒数据与大气环境数据,得到了碳钢的腐蚀速率方程;之后该小组还汇编了日本43个地区的暴露试验数据,分析得到了碳钢在内陆工业大气以及海洋大气环境中的腐蚀速率。 PRIETO等根据数据库收集的650多条粘合测试结果,构建了一个多元线性回归方程以评估腐蚀和未腐蚀钢筋的结合强度,确保钢筋混凝土构件的结构安全性。 由于仅研究环境数据具有很大的局限性,研究人员通过人工改变外界条件来进行腐蚀研究。王海杰等通过改变土壤中NaCl含量,对比分析了NaCl污染土中含气率、电阻率等,建立了Q235钢在污染土中的腐蚀质量损失率线性回归模型;廖柯喜等提出了L360管道在不同H2S分压、CO2分压、温度以及流速下的腐蚀速率预测线性回归模型。 线性回归方程对数据量要求不高,且能清晰表示因变量与各变量间的关系,但对数据本身的线性要求太高,因此使用范围有限。 02 曲线拟合方法 曲线拟合方法是预测材料腐蚀损失的常用模型。它是一种利用解析表达式逼近离散数据的方法,依据腐蚀规律建立函数,并利用试验数据对函数中的参数进行估计。由于并非每个变量之间都有严格的线性数学关系,对于复杂的非线性数据,可以采用通用而又简便的曲线进行拟合。 该方法利用连续散点图近似刻画数据,根据曲线类型,确定相应的解析表达式,建立函数模型,如利用幂函数模型,对数函数模型等。由于它具有精度高、适用范围广,通用性强的特点,一般情况下,选用最小二乘算法拟合,依照残差平方和最小的原则。 早在1975年,武钢钢铁研究所联合武汉大学数学系就利用最小二乘法原理尝试求得腐蚀回归方程,但数据量较少,影响了回归式的精确度。 曹楚南利用高斯-牛顿曲线拟合法对腐蚀金属的弱极化曲线进行拟合,估算了腐蚀过程电化学动力学参数,但这种方法在处理多参数情况时,容易出现不收敛的情况,为改善此情况,易忠胜等利用单纯形法优化拟合,提高了计算精度及收敛性。孙峰等提出基于粒子群-信赖域的极化曲线拟合算法,解决了拟合精度不高和结果陷入局部最优的问题。 除了以上典型模型外,韩庆华等基于三参数威布尔分布对铸钢及对接焊缝的腐蚀疲劳应力-寿命曲线进行修正,使该曲线具有更好的弯曲形状且提高了拟合精度;GAZENBILLER等发现在105~110 ℃下,AA-1050铝合金在无水乙醇温度诱导化学腐蚀试验中,最大腐蚀深度符合Gumbel统计规律,提出了醇类腐蚀机理。 相较于线性回归,曲线拟合在局限方面有了一定的进步,它不要求曲线通过所有已知点,得到近似曲线即可,但在拟合曲线前,需要先分析是曲线类型,这是一个困难的过程。 03 灰色关联分析和灰色预测 邓聚龙提出了灰色系统理论,包括了灰色建模、灰色预测、灰色关联分析等,是一种适用于分析数量少且信息贫乏的系统。灰色系统是部分信息已知而部分信息未知的系统,灰色系统理论就是提取部分已知信息中有价值的信息并进行相关性推演和预测。 常用灰色关联分析法来分析各腐蚀因素(如温度、湿度、降雨量等)对腐蚀速率的影响程度,对腐蚀因素进行强弱排序,寻找关键因素。 FU等利用灰色关联分析对影响油管的相关因素进行分析,发现造成油管腐蚀的主要因素是无硫腐蚀和油管中气体的腐蚀;CAO等在中国7个典型试验场进行为期1年的Q235钢腐蚀试验,采用灰色关联分析,将影响Q235钢的腐蚀因素进行排序,确定相对湿度是对Q235钢腐蚀影响最严重的因素;邓志安等对管线腐蚀速率与环境因素进行灰色关联分析,选取关联度较高的影响因素进行后续预测分析,降低了预测难度;WANG等研究了2Cr13不锈钢在模拟深海环境中的点蚀行为,通过灰色关联度计算,确定了各因素对不锈钢蚀坑深度的影响由大到小依次为:静水压力>溶解氧含量>温度,即在深海环境中,静水压力对碳钢蚀坑深度的影响最大。 然而该方法分配权重时主观性太强,会对计算结果产生客观影响,而且只能反映测试条件下的腐蚀因素对腐蚀速率的影响,无法做到普遍情况下的腐蚀情况推广。 灰色预测中GM(1,1)模型是描述灰色系统的最简单模型,在计算时只需要3~7条时序性数据即可进行挖掘,建模,预测腐蚀相关因素随时间的变化。但是,该模型在遇到随机性数据和进行中长期预测时,拟合效果不佳,可能会降低模型预测结果的准确度。 唐其环等应用灰色GM(1,1)模型对江津地区大气腐蚀结果进行了预测,但用于长期大气腐蚀预测时误差仍然较大;陈建设等基于热镀锌层在海水中的腐蚀规律建立了GM(1,1)模型,将整个腐蚀过程分为三段处理,使模型具有良好的拟合和预测精度;WANG等采用GM(1,1)模型预测了回火处理后的低合金钢在酸性溶液中的腐蚀速率,ZHANG等根据GM(1,1)模型推导了沥青路面性能的预测方程,以有效预测高速公路沥青路面的性能和腐蚀问题,结果表明该模型可行且能较好地用于腐蚀速率预测。 04 人工神经网络 人工神经网络(ANN)是模拟生物神经系统进行信息处理,由大量人工神经元相互连接而成的一个多输入、单输出的非线性元件。人工神经元是人工神经网络操作的基本单位,每个神经元都作为神经网络结构中一个节点,当人工神经元的加权和输入超过阈值时,就产生了神经输出,如图2所示。 图2 神经元模型 人工神经网络模型种类数量繁多,如BP神经网络、HOPFIELD网络、BERTYMEN模型、ART模型等,目前最常用的是由RUMELHART等提出的人工神经网络模型——反向传播(BP)神经网络,也是腐蚀研究中应用最广泛的网络学习方法。 神经网络以试验数据为基础,无需事先给定公式,经过有限次迭代后,可获得内在规律,因此神经网络技术适用于研究腐蚀系统的特征问题。 郭稚弧等尝试利用神经网络预测碳钢在土壤腐蚀中的腐蚀速率,证实了神经网络用于土壤腐蚀规律研究的可行性;DIZA等在研究碳钢损伤时,将湿度、SO2沉积量、降水、相对湿度(低于40%)、氯化物沉积量等作为神经网络的输入变量,与传统线性回归相比,神经网络能预测不同气候和污染条件下的碳钢损伤,有更好的预测性和置信区间;刘静等利用神经网络模型对316L不锈钢的临界点蚀温度(CPT)进行预测,预测结果与试验高度值吻合,能实现气田作业区耦合环境中的CPT的预测;LI等建立了三层BP神经网络模型,预测了碳钢在混合MDEA溶液中的腐蚀速率,输入层有5个输入变量,与拥有8个输入变量的支持向量机模型(SVM)相比,该模型更优。 然而,运用神经网络进行预测时,需要大量数据进行训练学习,否则容易造成过拟合。 05 支持向量机 支持向量机(SVM)是由VAPNIK等提出的,基于结构风险最小化原理和统计学习理论的一种有监督的新型学习方式。最初用来解决二分类问题,后来逐渐可以用于解决分类识别、小样本回归分析、密度函数估计等问题。 其核心是用直线将具有代表性的两部分数据尽可能分离,这些直线称为分隔超平面,在支持向量机理论中,需要找到这样一个直线即超平面进行分隔,但实际上会得到多组直线,此时通过直线的最大化可移动距离来确定最优解,在线性回归问题中,它将求解问题转化成了二次规划问题。如图3所示,Da<Db,可得最优解。 图3 支持向量的示意图 支持向量机在腐蚀预测中因具有优异的高维非线性数据处理能力,成为腐蚀数据挖掘中的常用方法。由于该方法是借助二次规划求解支持向量,因此在涉及大量数据、高阶矩阵计算时,将消耗大量内存和时间。 王大勋等引入支持向量机算法,研究了油田注水管道的腐蚀速率预测模型,提供了一种新的注水管道腐蚀预测方法;FU等将SVM算法用于大气腐蚀研究,利用小样本数据建立腐蚀速率预测模型,揭示了SVM算法在小样本问题中的优越性;周澄等在研究管道弯曲处腐蚀损伤程度智能辨识时,建立了支持向量机模型和BP神经网络模型来,对比研究了两种模型对弯管腐蚀损伤的辨识,结果表明,支持向量机在小样本条件下,相较于BP神经网络有更好的辨识效果。 06 贝叶斯网络 贝叶斯网络是基于贝叶斯理论发展而来的一种概率推理的图形化概率网络,于1988年由Judea Pearl提出,当时主要用来处理人工智能中的不确定信息。由于贝叶斯网络能够将知识经验融入网络节点,用节点变量表达各个信息要素,用连接节点间的有向边,表达各要素间的关系,且能处理不完整数据集,因此应用广泛。在腐蚀领域,贝叶斯网络则是侧重于描述变量间的因果关系。 胡明等在分析某天然气管道腐蚀因素时,利用贝叶斯网络分析原理,将确定的23个腐蚀失效因素作为贝叶斯网格的子节点,管线腐蚀失效作为根节点,通过各子节点间条件概率关系,得出子节点与根节点间的概率统计关系,从而来指导天然气管道系统的维护和维修;左哲研究了长输管道泄漏及蒸气云爆炸事故的演化规律,对埋地管线发生泄漏的四个阶段进行了分析,构建了贝叶斯网络模型,证明贝叶斯网络在描述事故过程中间节点事件间依赖关系时有较大优势;GUO等在研究腐蚀坑形态和尺寸与应力集中系数之间的关系时,提出了应力集中贝叶斯预测模型,利用腐蚀坑的宽深比和长宽比来评价应力集中体系,预测结果有较高的准确性。 07 梯度提升决策树 决策树是一种基于树形结构的应用广泛的分类与回归方法,如图4所示。 图4 决策树示意图 决策树通常分为:特征选择、决策树的生长、以及剪枝。通过对训练集进行学习,以树形样式将数据决策与数据分类过程清晰呈现,这种算法相对简单、直观,具有较好的鲁棒性。但是单棵树依旧不稳定,随着决策树的生长和样本量的不断减小深入,样本对总体的代表性不断减小,一般性越来越差,细微的数据变化极有可能得到完全不同的结果,且即使剪枝也易发生过拟合现象。 梯度提升决策树是基于梯度提升框架的改良决策树算法,也是近年来最有效的方法之一,通过每次迭代,在减少残差的方向上建立了一颗新的决策树模型,并通过各级新的决策树加权构成新的决策树模型。相较于单棵决策树,梯度提升决策树拥有更好的健壮性及泛化性,有效提高了分类及预测结果的准确性。 李秋实将梯度提升决策树模型应用在电化学噪声处理的腐蚀类型判别,对混合两种数据样本的腐蚀类型进行判别,准确性高达98.4%,且拥有传统腐蚀类型判别方法所无法实现的普适性。梁喜旺等则利用梯度提升树建立了大气腐蚀预测模型,与单棵回归树相比,预测效果误差降低了近一半。 08 随机森林 随机森林是由BREIMAN在2001年提出的一种统计学习理论,通过集成学习思想将多个弱分类器的决策树模型组成一个强分类器,其建模过程就是多个树模型的学习过程,如图5所示。 图5 随机森林模型示意图 随机森林模型改善了单棵决策树在小样本处理中出现的过拟合现象,具有易于实现、鲁棒性、可解释性好、稳定、适合处理高维数据、不受噪声影响等优点,是一种自然的非线性建模工具,因此随机森林模型在生物、农业、医学、风险评价等领域都有广泛的应用。从2016年起,随机森林就开始被运用在腐蚀领域。 MORIZET等将随机森林与k-最近邻算法进行了比较,后将随机森林与小波分析进行结合,提出了一种分离局部腐蚀信号的新方法;HOU等采用电化学噪声法研究碳钢在保温矿棉下腐蚀性能,并用随机森林模型来识别腐蚀类型;YAN等将钢的化学成分和环境因素映射到相应环境条件下低合金钢的腐蚀速率中,建立了随机森林模型,实现了准确的腐蚀速率预测,且得出环境腐蚀性的决定因素为空气中Cl-的沉积速率。此外,还论证了随机森林模型、CART回归树、RF随机森林三种方法对新环境中钢样的腐蚀预测能力,结果表明随机森林模型的预测能力优于其他模型。 09 聚类分析 聚类是一种无监督学习模式,常用来寻找数据之间内在结构关联性与差异性。它通过一定规则的数据集划分为相似的若干个类,认为两个目标间距离越近,相似度越大,这些相似组被称为簇,要保证每个簇中数据具有相似性,不同簇之间具有差异性,可通过归并每一簇间的特性来概括整个数据集或者用作其他模型的输入。 在腐蚀领域,影响腐蚀的因素复杂多样,常采用该方法对各因素进行聚类分析从而评估各影响因素。朱超慧在研究影响高含硫管道腐蚀因子间关系时,采用了因子分析、相关分析和聚类分析三种方法,聚类分析从整体出发对整个样本进行合理的分类,增加了数据分析的合理性;张腾等基于系统聚类方法,根据大气腐蚀的差异性,将17个典型地区进行了分类,确定了我国大气腐蚀分区个数和各区的划分标准;周健科等对配电网引流线进行聚类分析,提取了海岛微气象环境中的空间故障规律,划分失效评估区域,有效提升引流线失效评估模型准确性。 10 模糊理论 模糊集是L.A.Zadeh于1965年提出的概念,最初用来解决控制领域的疑难,后来随着模糊逻辑和模糊理论等的发展,模糊集方法也被用于数据挖掘的分类和回归任务中。 模糊理论针对原本无法归入集合的模糊数据,将经典集合的外延模糊,使这些具有模糊属性的对象归入模糊集合,能够被量化统计。模糊集合和模糊逻辑的定义合理反映了现实世界数据间的关系,可以改善模型的预测性能,对模糊规则的应用可以提高模型的可解释性。 安新正等基于模糊理论建立了高桥墩工作性能损伤模糊综合评价方法,采用此法对某钢筋混凝土高桥墩的工作性能进行评价,结果与现场调查的工况基本一致;雷云等利用模糊理论处理经专家评估的影响海底管道失效的各风险因素后,利用软件进行计算,进行模糊综合评估,结果表明在役管道的风险等级较低,并确定海底管道失效的主要原因,这些也与事故统计结果基本一致。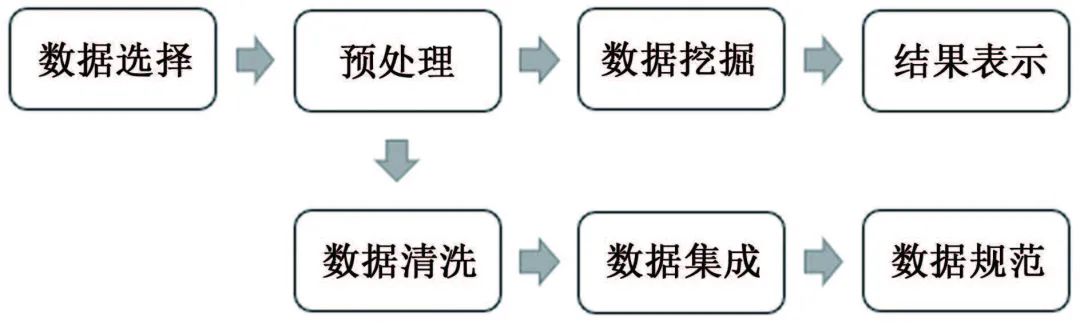
2
腐蚀中集成算法的应用 ❤ 传统的方法是在一个可能的函数构成的空间中寻找一个最接近实际模型的预测器,例如上述提到的多元线性回归、人工神经网络、贝叶斯网络等等。近年来,传统的单一模型往往精度不高,且容易出现过拟合问题。因此,国内外学者将目光转向通过集成多个算法模型来进行预测和分类,改善单一模型带来的弊端。集成学习通过组合多种弱分类器,将对应不同特征能力的模型有效结合起来,得到了一个强学习器,从而提升了模型的精确度。以下列举了几种常用的集成优化模型。 单一神经网络模型具有卓越的数据处理能力和学习能力,被广泛应用在腐蚀领域,当腐蚀数据量充足时,其预测性能优于很多其他预测模型。当样本量不足时,结合其他算法模型的集成模型在很大程度上提高了预测的准确性,解决了因数据量小而出现的过拟合等问题。 刘威等将神经网络与灰色理论相结合,形成灰色-神经网络模型进行腐蚀预测;凌晓等选择用遗传算法来优化BPNN模型;王金秋等提出了粗糙集-BP神经网络预测模型;肖斌等提出了一种改进的粒子群算法优化的神经网络算法(IPSO-BPNN),这些算法结果证明优化后的结果比单一模型结果要更加精确。 SVM是一种能在小样本条件下进行预测的方法,为了进行更准确地预测,骆正山等基于灰色向量机来建立管道腐蚀预测模型;李响等通过遗传算法改进SVM模型来进行海洋环境腐蚀预测,有效降低了预测误差;SONG等在研究车辆船舶运行条件下碳钢动态腐蚀时,构建遗传算法优化支持向量回归模型(GA-SVR)、遗传算法优化BP神经网络模型(GA-BPNN)、未优化SVR和未优化BPNN4个模型,预测碳钢在动态环境中的腐蚀速率,最终结果表明GA-SVR的均方根误差跟平均相对误差最小;LU等提出了利用3D坐标量化数字参数来描述生锈钢筋的横截面形态,并且建立了粒子群优化支持向量机模型(PSO-SVM)和网格搜索支持向量机模型(GS-SVM)两种优化模型来进行钢的截面腐蚀率预测,两种腐蚀预测模型的预测结果都比较准确,最后相比之下,PSO-SVM的精度要优于GS-SVM。 随机森林本来就是集成算法的一种,相较于本身单一的决策树模型,随机森林模型优点更多,更加适用于腐蚀速率预测模型的建立,也是近年来的研究热点。ZHI等提出了一种新的深度结构模型,全连接级联动态集成选择森林算法(DCGF-WKNN),用来实现腐蚀建模数据预测,与单一算法模型人工神经网络(ANN)、支持向量回归(SVR)等相比,该方法能够获得最佳的预测效果。
3
结论与展望 ❤ 目前,人们对腐蚀领域的数据挖掘方法进行了广泛的研究,揭示了隐藏于数据背后的腐蚀信息、建立了腐蚀损伤预测模型,但将其成熟应用于指导工程实践还需要开展更深入的研究以及更长时间的检验。 (1) 在腐蚀数据挖掘研究的早期,受腐蚀数据采集技术的限制,数据样本有限,相关研究主要是对数据进行回归、拟合,揭示环境因素影响腐蚀的规律,构建剂量响应方程用于腐蚀预测。随着腐蚀数据的持续性积累与人工智能技术的兴起,部分机器学习的方法如支持向量机、人工神经网络、随机森林等技术被移植应用于腐蚀数据挖掘并取得了较好的效果,但绝大多数模型对应用边界具有严格的限定,泛化能力较差,限制了其应用。 (2) 随着近些年信息技术的快速发展,腐蚀在线监测设备在许多领域得到应用,腐蚀数据实现了连续性采集以及数据、图像、视频等多维表现,腐蚀数据是数量极其庞大且具有时序性的,腐蚀数据挖掘更适于采用大数据分析和处理的方法,在后续的研究中,多种算法的集成应用将更有利于扩展模型的使用边界、提高分析或模拟结果的准确性。与此同时,与连续性采集的腐蚀数据不相匹配的是部分影响腐蚀进程的关键环境特征参数的在线监测技术还有待于进一步研究开发,以保障数据挖掘过程中腐蚀数据关键数据项的完整性。
免责声明:本网站所转载的文字、图片与视频资料版权归原创作者所有,如果涉及侵权,请第一时间联系本网删除。
相关文章

官方微信
《腐蚀与防护网电子期刊》征订启事
- 投稿联系:编辑部
- 电话:010-62316606-806
- 邮箱:fsfhzy666@163.com
- 腐蚀与防护网官方QQ群:140808414
点击排行
PPT新闻

“海洋金属”——钛合金在舰船的
点击数:8398

腐蚀与“海上丝绸之路”
点击数:6744