




第一作者:王萍。通讯作者:袁睿豪
通讯单位:西北工业大学凝固国家重点实验室
文章链接:
https://www.sciencedirect.com/science/article/pii/S1359645425005622
描述符是基于机器学习的材料设计取得成功的关键先决条件。然而,如何为各种性能自动构建可泛化的描述符,并将其与设计标准相结合,仍然是一个长期存在的挑战。本文通过设计一个整合了大型语言模型、领域理论约束([Mo]eq和d-电子理论)以及多目标全局优化的框架来克服这一难题。该框架融合了结构化(表格化的成分/加工数据)和非结构化(文本)数据,以获得信息更丰富的描述符,从而促进材料设计。我们以钛合金为案例,首先自动获得了可很好地泛化于各种性能的描述符,从而实现了预测模型的优化。在此基础上,我们提出了一种设计流程,从庞大的化学和加工空间中识别出几种具有高潜力的、可增强竞争性能的合金,并通过实验合成验证了其可靠性。研究表明,从约50,000篇没有明确物理学的文本中学习到的丰富描述符,能够捕捉到与相稳定性、特定性能的合金化规则等相关的专业知识。我们提出的方法可应用于描述符尚不完善且结构化数据有限的其他材料设计领域。
背景介绍:
传统描述符局限性:传统描述符如元素含量、时效温度所传达的信息往往不足,导致机器学习模型和后续材料设计的效果不佳。这种问题在材料科学中尤为突出,尤其是可用于建模的数据有限。
现有丰富描述符信息量方法:基于物理的描述符,虽然可以通过引入基于物理的量(如相变相关属性、热力学指标)来丰富描述符信息量,但它们通常是特定于性质的,并且其选择高度依赖于领域专业知识。基于坐标的编码,这类方法(如编码原子环境的矩阵)需要精心定义的编码规则,且仅适用于符合这些规则的材料。现有方法都难以自动获得适用于各种性质的、可泛化的描述符,并将其与材料设计标准结合起来。
主要图片预览:
大量的非结构化文本数据(如科学论文)蕴含着丰富的隐性知识,却难以被现有机器学习算法直接利用。尽管近期语言模型在处理材料文本方面取得了进展,但它们仍未实现自动构建出能泛化到未知材料和多样性质的通用描述符,这限制了在大规模材料空间中进行有效搜索的能力。为突破这一瓶颈,我们提出了一种创新性框架(图1),其核心在于有效融合非结构化文本数据与结构化数据。以钛合金设计为例,我们利用该框架从海量文本中自动学习并重构了合金成分,生成了通用性强的描述符。这些描述符不仅显著提升了不同性质和算法的预测模型性能,更重要的是,结合领域理论和高效优化,我们成功从广阔的化学与加工空间中筛选出了多个有望打破传统强度-延展性或强度-模量权衡的合金。
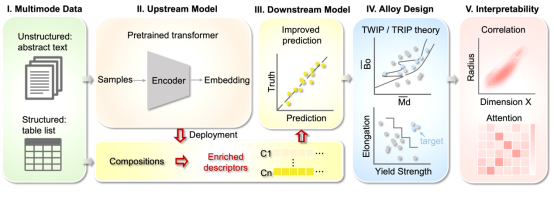
图 1. 本研究的工作流程如下:I. 多模态数据的收集与处理;II. 上游语言模型的训练;III. 合金成分的丰富描述符生成及下游回归模型的训练;IV. 将回归模型与领域理论和多目标优化相结合,设计具有竞争性能的亚稳态钛合金;V. 可解释性分析。
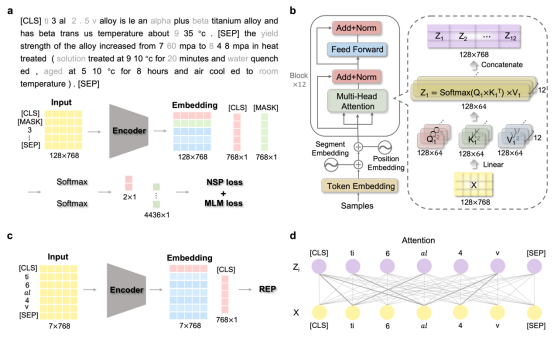
图 2. 大型语言模型的训练和部署。(a) 训练样本的格式(灰色标记表示被掩码的样本)以及通过 NSP 和 MLM 损失优化参数的语言模型的预训练过程。(b) Transformer-Encoder 模型的具体架构。(c) 部署 Transformer 以丰富钛合金成分的表示。(d) 注意力机制示意图。
图2a展示了LLM的训练流程,包括使用超过46,000篇摘要构建正负样本进行训练,并利用MLM和NSP损失函数进行优化。图2b进一步解析了LLM的输入构成以及模型架构。图2c展示了模型在推理阶段为合金成分生成嵌入向量。图2d则深入描绘了Transformer架构的核心,即自注意力机制,它能高效处理长序列并捕捉tokens之间复杂的语义和结构关系。鉴于LLM最初生成的768维描述符维度过高,制定了一系列降维策略。先使用皮尔逊相关性分析,接着运用遗传算法(GA)进一步将维度优化至与传统描述符相同的13维。以拉伸强度为例,图3展示了GA如何通过迭代优化,使得最优描述符组合的R2值迅速收敛并稳定,从而确定了适用于不同性能预测的最佳13维丰富描述符集合。
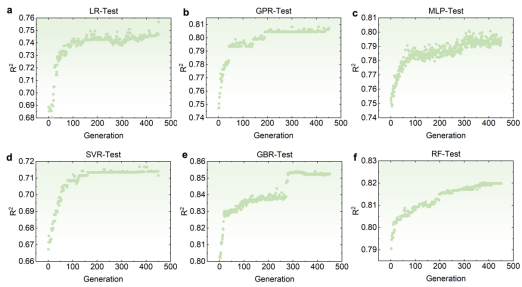
图3. 以拉伸强度为例,通过遗传算法优化选择六个下游回归模型的丰富描述符。(a)LR,(b)GPR,(c)MLP,(d)SVR,(e)GBR,(f)RF。
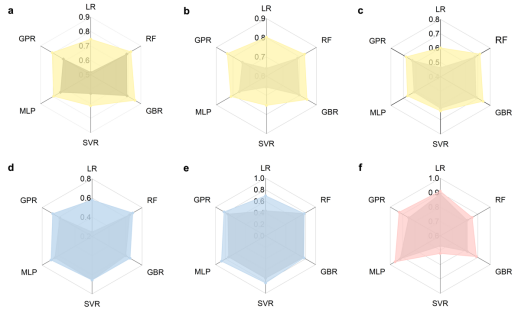
图 4. 基于常规描述符(深色)和丰富描述符的回归模型性能比较。每个模型的指标均来自测试集,采用五重交叉验证。(a)、(b) 和 (c) 分别表示数据 S2 中的拉伸强度、屈服强度和伸长率。(d)–(e) 分别表示数据 S3 中的屈服强度和弹性模量。(f) 分别表示数据 S4 中的蠕变断裂寿命。
图4展示了本研究中丰富描述符在预测多种材料性能方面的卓越表现,并将其与传统描述符进行了对比。这些结果清晰地表明,通过Transformer模型自动构建的丰富描述符对于不同的回归算法和多种材料性能都具有良好的泛化能力。
图5详细阐述了本研究如何通过融合领域理论与机器学习来加速亚稳态钛合金设计。首先利用钼当量和d电子理论对百万级候选合金进行预筛选,随后结合丰富描述符、加工参数输入机器学习模型进行性能预测和多目标优化(如平衡强度-延展性),最终通过对实际合成合金的验证,成功筛选出并证实了具有突破性竞争性能的新型合金。
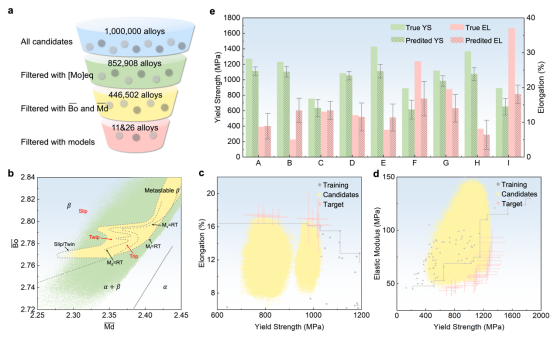
图5. 钛合金设计与实验验证。(a) 亚稳态合金设计流程。(b) 根据d电子理论图筛选亚稳态合金(黄色区域),以不同的相和变形机制(从右到左依次为滑移、TWIP、TRIP)为特征。(c) 针对具有更高屈服强度和伸长率的候选合金进行多目标优化;(d) 屈服强度和弹性模量。 (e) 验证建议的可靠性(A:Ti–5.2Mo–5.2Cr–4.0Al–4.4V–2.4Nb,B:Ti–5Al–5Mo–5V–3Cr–0.6Fe,C 和 D:不同加工的 Ti–6Mo–5V–3Al–2Fe,E:Ti–15.1V–3.1Al–2.5Cr–2.9Sn,F:Ti–11V,G:Ti–5Al–5Mo–5V–3Cr–1Zr,H:Ti–7.18Mo–2.99Nb–2.94Cr–3Al,I:Ti–1Al–8.5Mo–2.8Cr–2.7Zr)。
图6深入剖析了本研究中丰富描述符的卓越性能来源,主要揭示了其编码的物理知识和捕获专家经验的能力。在编码物理知识方面,图6a展示了描述符如何自发地从大量文本中学习并区分不同元素对合金相稳定性的影响,将元素精准分类;同时,图6b和图6c通过高皮尔逊相关系数证明,这些描述符甚至能在未明确输入物理信息的情况下,隐含地捕捉到如价电子浓度和原子半径等核心物理属性,印证了大型语言模型学习文本中潜在物理规律的强大能力。在捕获专家经验方面,图6d至图6i通过可视化Transformer模型的注意力矩阵,揭示了描述符如何像人类专家一样,识别出对特定材料性能(如高延展性、高强度或低模量)至关重要的合金元素,这与现有材料科学研究的结论高度吻合。
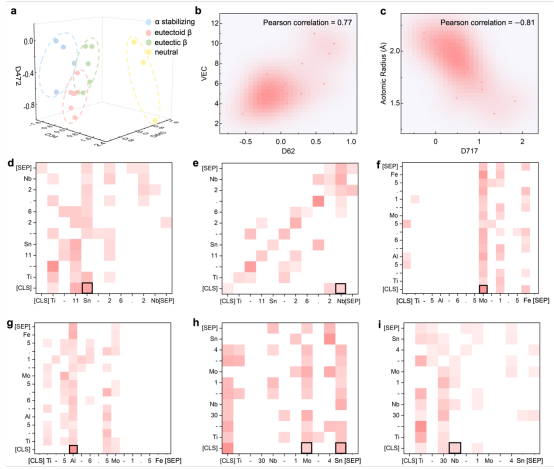
图 6. 丰富描述符的可解释性分析。(a)基于大型语言模型生成的嵌入对各种相稳定性元素进行聚类。(b)VEC 与嵌入第 62 维之间的 Pearson 相关性;(c)原子半径与嵌入第 717 维之间的 Pearson 相关性。第 12 个区块中,每种合金成分的两个典型注意力头对应的注意力矩阵如下:(d)和(e)代表 Ti-11Sn-26.2Nb,(f)和(g)代表 Ti-5Al-6.5Mo-1.5Fe,(h)和(i)代表 Ti-30Nb-1Mo-4Sn。颜色越深,表示两个标记之间的注意力水平越高。
免责声明:本网站所转载的文字、图片与视频资料版权归原创作者所有,如果涉及侵权,请第一时间联系本网删除。

官方微信
《腐蚀与防护网电子期刊》征订启事
- 投稿联系:编辑部
- 电话:010-62316606
- 邮箱:fsfhzy666@163.com
- 腐蚀与防护网官方QQ群:140808414

“海洋金属”——钛合金在舰船的

腐蚀与“海上丝绸之路”