耐腐蚀新材料研究进入大数据新时代,北京科技大学用AI新范式“算”出新材料
2024-05-30 16:23:08
作者:腐蚀与防护 来源:腐蚀与防护
分享至:
在北京科技大学科技楼里,温度、湿度、腐蚀电流、腐蚀等级……来自海上风电、地下管网、川藏地区重点工程等全国各地典型环境和场景的数据,正在源源不断地实时传输到国家材料腐蚀与防护科学数据中心(以下简称腐蚀数据中心)的数据存储系统和展示平台上。
国家材料腐蚀与防护科学数据中心常务副主任、北京材料基因工程高精尖创新中心副主任张达威将腐蚀数据中心的工作概括为“给材料看病”,而这些监测系统收集来的数据,相当于积累了越来越多的“病例”。“目前我们的主要任务是从这些‘病例’中挖掘更多可以‘喂’给人工智能的信息,即利用‘大数据+人工智能’技术,加速耐腐蚀新材料的发现、开发、生产、应用等流程。”近日,张达威在接受记者采访时说。材料腐蚀研究长期以来是我国科研工作者的重要课题。北京科技大学是我国材料腐蚀研究的发源地之一。在国家大力推进科学数据共享应用的背景下,腐蚀数据中心于2019年在该校成立,成为全国20个科学数据中心之一。
该中心的主要任务就是整合资源,打造国家级材料腐蚀数据生产平台,同时基于这些数据进行研究,开展材料基因工程模式下先进耐蚀材料与防护技术协同研究。数据采集是第一步。此前,科学家们主要通过在典型服役环境进行挂片实验来收集腐蚀数据。“几代科学家在几十年间,艰难积累了几千万条腐蚀数据。”张达威说,但这些数据连续性不强,很难精确反映动态、多变的环境因素对腐蚀过程的影响。
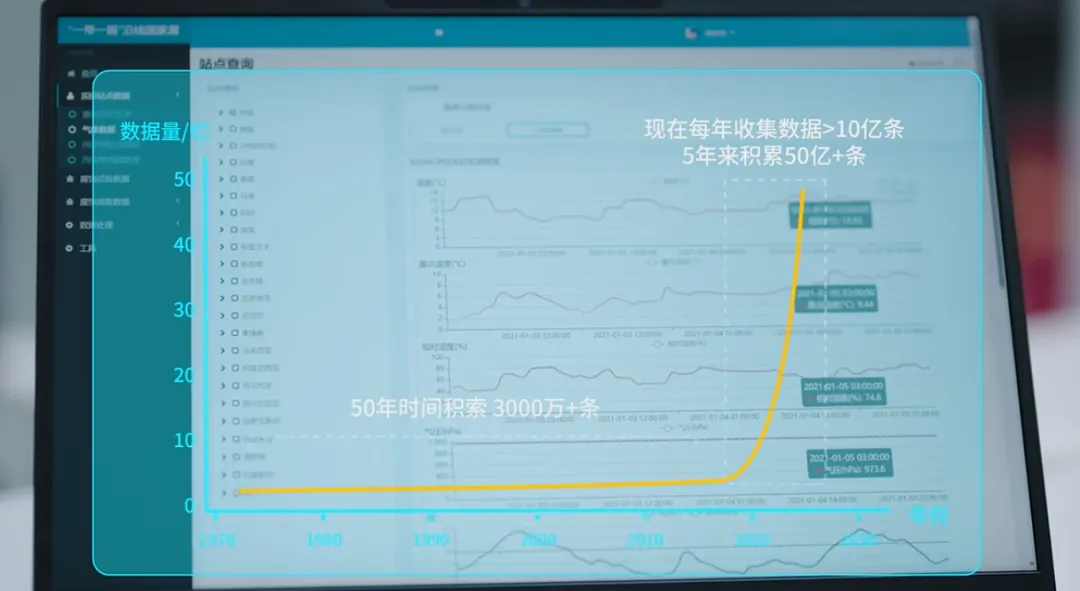
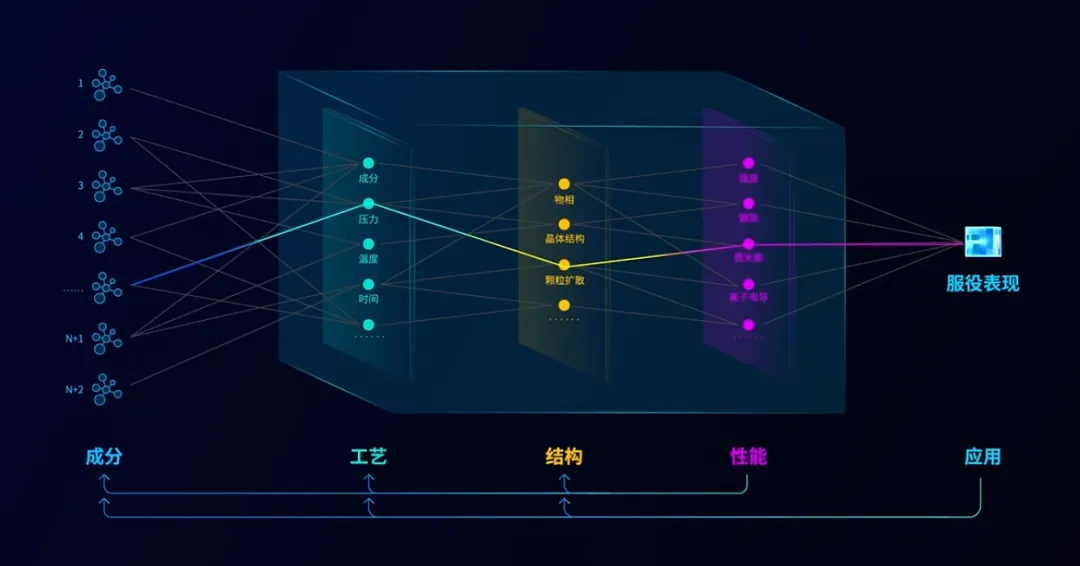
“如今,我们的材料腐蚀研究已进入大数据新时代。”张达威说,通过腐蚀在线监测系统融合新型腐蚀监测传感器技术与先进物联网技术,该中心建立了全球最大的材料腐蚀数据采集网络。同时,该中心建成了拥有近千种关键材料、50多亿条数据的全球最大材料腐蚀数据库。基于这些数据,该中心开发了高品质低合金耐蚀钢和长寿命智能防腐涂层等新材料。“我们正在构建第五代材料腐蚀数据库,通俗来说就是,进一步解读源源不断产生的海量数据,找到它们之间的关联,让它们能智能关联检索,让这个数据库更‘聪明’。”张达威说。“要想实现这一目标,需要强大的算力和算法的支撑。”张达威说。传统的新材料研究主要以实验驱动,又被称为“试错式”研究方法,通过改变材料成分、合成手段、工艺参数等条件制备系列样品,选出其中性能最合适的材料。“这种传统方式依赖于经验和理论,需要经历反复实验,材料研发周期长、成本高。”张达威说,如今,新材料研发已进入数据驱动阶段,数据是基础,计算是关键。以耐蚀材料研发为例,材料腐蚀过程机理十分复杂,温度、湿度、应力等环境因素,成分、加工、结构等材料因素,时间尺度等累积效应,都是材料需要考虑的因素。张达威说,在防腐涂层的研究领域,科研人员要在成千上万种缓蚀成分中筛选缓蚀性能最佳的体系;有了大量数据的支撑,就可以针对不同金属材料、不同腐蚀环境进行缓蚀成分的高效筛选和设计,极大提升研发效率。

在耐蚀材料和防护技术的研发过程中,需要调控的变量众多,使用传统的实验方法,这样的实验要做成百上千次,往往无法得到最优解。“现在,我们利用人工智能技术,通过不同的腐蚀预测模型,对材料性能进行仿真测试,就可以快速得到材料在不同环境下的效果。”张达威说。因此,新材料研发周期从以前的10~20年缩短到3~5年甚至更短,“算”出新材料成为可能。
他分析道,在以前通过经验试错传统方法研发材料的时代,发达国家积累的大量数据我们无从得知,差距也很难追赶;而现在,快速获取海量数据并由数据反哺新材料研发成为可能。“我们将进一步与浪潮信息等提供算力基础设施的企业加强合作,通过算力,将数据转化为知识和价值,助力我国新材料的研发。”张达威说。近日,国家数据局等17部门联合印发的《“数据要素×”三年行动计划(2024—2026年)》指出,以科学数据支撑技术创新,聚焦生物育种、新材料创制、药物研发等领域,以数智融合加速技术创新和产业升级。该中心在算力支撑下,在新材料研发中充分发挥了数据要素的乘数效应,“算”出了新材料。
免责声明:本网站所转载的文字、图片与视频资料版权归原创作者所有,如果涉及侵权,请第一时间联系本网删除。